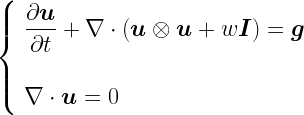Introduction
The recent update of The Data & Analytics Dictionary featured an entry on Charts. Entries in The Dictionary are intended to be relatively brief [1] and also the layout does not allow for many illustrations. Given this, I have used The Dictionary entries as a basis for this slightly expanded article on the subject of chart types.
A Chart is a way to organise and Visualise Data with the general objective of making it easier to understand and – in particular – to discern trends and relationships. This article will cover some of the most frequently used Chart types, which appear in alphabetical order.
Note:
Here an “axis” is a fixed reference line (sometimes invisible for stylistic reasons) which typically goes vertically up the page or horizontally from left to right across the page (but see also Radar Charts). Categories and values (see below) are plotted on axes. Most charts have two axes. Throughout I use the word “category” to refer to something discrete that is plotted on an axis, for example France, Germany, Italy and The UK, or 2016, 2017, 2018 and 2019. I use the word “value” to refer to something more continuous plotted on an axis, such as sales or number of items etc. With a few exceptions, the Charts described below plot values against categories. Both Bubble Charts and Scatter Charts plot values against other values.
I use “series” to mean sets of categories and values. So if the categories are France, Germany, Italy and The UK; and the values are sales; then different series may pertain to sales of different products by country. |

| Bar & Column Charts | Bubble Charts | Cartograms |
| Histograms | Line Charts | Map Charts |
| Pie Charts | Radar Charts / Spider Charts | Scatter Charts |
| Tree Maps |
Bar & Column Charts
Clustered Bar Charts, Stacked Bar Charts

Bar Charts is the generic term, but this is sometimes reserved for charts where the categories appear on the vertical axis, with Column Charts being those where categories appear on the horizontal axis. In either case, the chart has a series of categories along one axis. Extending righwards (or upwards) from each category is a rectangle whose width (height) is proportional to the value associated with this category. For example if the categories related to products, then the size of rectangle appearing against Product A might be proportional to the number sold, or the value of such sales.

The exhibit above, which is excerpted from Data Visualisation – A Scientific Treatment, is a compound one in which two bar charts feature prominently.

Sometimes the bars are clustered to allow multiple series to be charted side-by-side, for example yearly sales for 2015 to 2018 might appear against each product category. Or – as above – sales for Product A and Product B may both be shown by country.

Another approach is to stack bars or columns on top of each other, something that is sometimes useful when comparing how the make-up of something has changed.
See also: a section of As Nice as Pie

Bubble Charts are used to display three dimensions of data on a two dimensional chart. A circle is placed with its centre at a value on the horizontal and vertical axes according to the first two dimensions of data, but then then the area (or less commonly the diameter [2]) of the circle reflects the third dimension. The result is reminiscent of a glass of champagne (then maybe this says more about the author than anything else).

You can also use bubble charts in a quite visceral way, as exemplified by the chart above. The vertical axis plots the number of satellites of the four giant planets in the Solar System. The horizontal axis plots the closest that they ever come to the Sun. The size of the planets themselves is proportional to their relative sizes.
See also: Data Visualisation according to a Four-year-old

There does not seem to be a generally accepted definition of Cartograms. Some authorities describe them as any diagram using a map to display statistical data; I cover this type of general chart in Map Charts below. Instead I will define a Cartogram more narrowly as a geographic map where areas of map sections are changed to be proportional to some other value; resulting in a distorted map. So, in a map of Europe, the size of countries might be increased or decreased so that their new areas are proportional to each country’s GDP.

Alternatively the above cartogram of the United States has been distorted (and coloured) to emphasise the population of each state. The dark blue of California and the slightly less dark blues of Texas, Florida and New York dominate the map.

A type of Bar Chart (typically with categories along the horizontal axis) where the categories are bins (or buckets) and the bars are proportional to the number of items falling into a bin. For example, the bins might be ranges of ages, say 0 to 19, 20 to 39, 30 to 49 and 50+ and the bars appearing against each might be the UK female population falling into each bin.

The diagram above is a bipartite quasi-histogram [3] that I created to illustrate another article. It is not a true histogram as it shows percentages for and against in each bin rather than overall frequencies.

In the same article, I addressed this shortcoming with a second view of the same data, which is more histogram-like (apart from having a total category) and appears above. The point that I was making related to how Data Visualisation can both inform and mislead depending on the presentational choices taken.
Line Charts
Fan Charts, Area Charts

These typically have categories across the horizontal axis and could be considered as a set of line segments joining up the tops of what would be the rectangles on a Bar Chart. Clearly multiple lines, associated with multiple series, can be plotted simultaneously without the need to cluster rectangles as is required with Bar Charts. Lines can also be used to join up the points on Scatter Charts assuming that these are sufficiently well ordered to support this.

Adaptations of Line Charts can also be used to show the probability of uncertain future events as per the exhibit above. The single red line shows the actual value of some metric up to the middle section of the chart. Thereafter it is the central prediction of a range of possible values. Lying above and below it are shaded areas which show bands of probability. For example it may be that the probability of the actual value falling within the area that has the darkest shading is 50%. A further example is contained in Limitations of Business Intelligence. Such charts are sometimes called Fan Charts.

Another type of Line Chart is the Area Chart. If we can think of a regular Line Chart as linking the tops of an invisible Bar Chart, then an Area Chart links the tops of an invisible Stacked Bar Chart. The effect is that how a band expands and contracts as we move across the chart shows how the contribution this category makes to the whole changes over time (or whatever other category we choose for the horizontal axis).
See also: The first exhibit in New Thinking, Old Thinking and a Fairytale

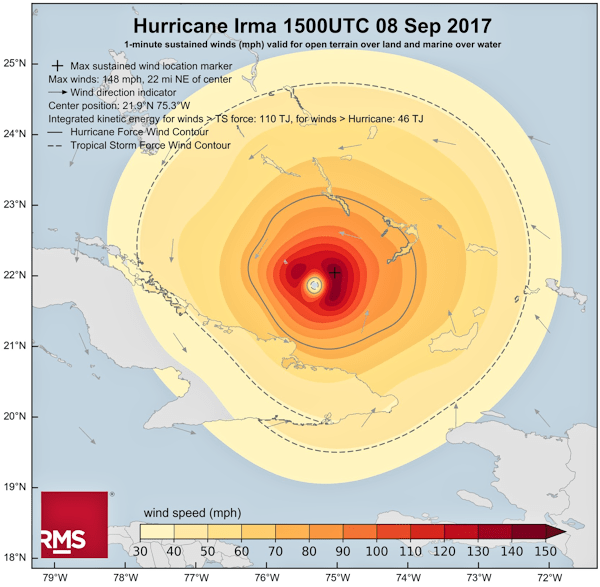
These place data on top of geographic maps. If we consider the canonical example of a map of the US divided into states, then the degree of shading of each state could be proportional to some state-related data (e.g. average income quartile of residents). Or more simply, figures could appear against each state. Bubbles could be placed at the location of major cities (or maybe a bubble per country or state etc.) with their size relating to some aspect of the locale (e.g.population). An example of this approach might be a map of US states with their relative populations denoted by Bubble area.

Also data could be overlaid on a map, for example – as shown above – coloured bands corresponding to different intensities of rainfall in different areas. This exhibit is excerpted from Hurricanes and Data Visualisation: Part I – Rainbow’s Gravity.

These circular charts normally display a single series of categories with values, showing the proportion each category contributes to the total. For example a series might be the nations that make up the United Kingdom and their populations: England 55.62 million people, Scotland 5.43 million, Wales 3.13 million and Northern Ireland 1.87 million.

The whole circle represents the total of all the category values (e.g. the UK population of 66.05 million people [4]). The ratio of a segment’s angle to 360° (i.e. the whole circle) is equal to the percentage of the total represented by the linked category’s value (e.g. Scotland is 8.2% of the UK population and so will have a segment with an angle of just under 30°).

Sometimes – as illustrated above – the segments are “exploded”away from each other. This is taken from the same article as the other voting analysis exhibits.
See also: As Nice as Pie, which examines the pros and cons of this type of chart in some depth.

Radar Charts are used to plot one or more series of categories with values that fall into the same range. If there are six categories, then each has its own axis called a radius and the six of these radiate at equal angles from a central point. The calibration of each radial axis is the same. For example Radar Charts are often used to show ratings (say from 5 = Excellent to 1 = Poor) so each radius will have five points on it, typically with low ratings at the centre and high ones at the periphery. Lines join the values plotted on each adjacent radius, forming a jagged loop. Where more than one series is plotted, the relative scores can be easily compared. A sense of aggregate ratings can also be garnered by seeing how much of the plot of one series lies inside or outside of another.

I use Radar Charts myself extensively when assessing organisations’ data capabilities. The above exhibit shows how an organisation ranks in five areas relating to Data Architecture compared to the best in their industry sector [5].

In most of the cases we have dealt with to date, one axis has contained discrete categories and the other continuous values (though our rating example for the Radar Chart) had discrete categories and values). For a Scatter Chart both axes plot values, either continuous or discrete. A series would consist of a set of pairs of values, one to plotted on the horizontal axis and one to be plotted on the vertical axis. For example a series might be a number of pairs of midday temperature (to be plotted on the horizontal axis) and sales of ice cream (to be plotted on the vertical axis). As may be deduced from the example, often the intention is to establish a link between the pairs of values – do ice cream sales increase with temperature? This aspect can be highlighted by drawing a line of best fit on the chart; one that minimises the total distance between each plotted point and the line. Further series, say sales of coffee versus midday temperature can be added.
Here is a further example, which illustrates potential correlation between two sets of data, one on the x-axis and the other on the y-axis:

As always a note of caution must be introduced when looking to establish correlations using scatter graphs. The inimitable Randall Munroe of xkcd.com [7] explains this pithility as follows:

See also: Linear Regression

Tree Maps require a little bit of explanation. The best way to understand them is to start with something more familiar, a hierarchy diagram with three levels (i.e. something like an organisation chart). Consider a cafe that sells beverages, so we have a top level box labeled Beverages. The Beverages box splits into Hot Beverages and Cold Beverages at level 2. At level 3, Hot Beverages splits into Tea, Coffee, Herbal Tea and Hot Chocolate; Cold Beverages splits into Still Water, Sparkling Water, Juices and Soda. So there is one box at level 1, two at level 2 and eight at level 3. As ever a picture paints a thousand words:

Next let’s also label each of the boxes with the value of sales in the last week. If you add up the sales for Tea, Coffee, Herbal Tea and Hot Chocolate we obviously get the sales for Hot Beverages.

A Tree Map takes this idea and expands on it. A Tree Map using the data from our example above might look like this:

First, instead of being linked by lines, boxes at level 3 (leaves let’s say) appear within their parent box at level 2 (branches maybe) and the level 2 boxes appear within the overall level 1 box (the whole tree); so everything is nested. Sometimes, as is the case above, rather than having the level 2 boxes drawn explicitly, the level 3 boxes might be colour coded. So above Tea, Coffee, Herbal Tea and Hot Chocolate are mid-grey and the rest are dark grey.
Next, the size of each box (at whatever level) is proportional to the value associated with it. In our example, 66.7% of sales (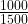

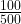
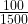
It is probably obvious from the above, but it is non-trivial to find a layout that has all the boxes at the right size, particularly if you want to do something else, like have the size of boxes increase from left to right. This is a task generally best left to some software to figure out.
In Closing
The above review of various chart types is not intended to be exhaustive. For example, it doesn’t include Waterfall Charts [8], Stock Market Charts (or Open / High / Low / Close Charts [9]), or 3D Surface Charts [10] (which seldom are of much utility outside of Science and Engineering in my experience). There are also a number of other more recherché charts that may be useful in certain niche areas. However, I hope we have covered some of the more common types of charts and provided some helpful background on both their construction and usage.
Notes
| [1] |
Certainly by my normal standards! |
| [2] |
Research suggests that humans are more attuned to comparing areas of circles than say their diameters. |
| [3] |
© peterjamesthomas.com Ltd. (2019). |
| [4] |
Excluding overseas territories. |
| [5] |
This has been suitably redacted of course. Typically there are four other such exhibits in my assessment pack: Data Strategy, Data Organisation, MI & Analytics and Data Controls, together with a summary radar chart across all five lower level ones. |
| [6] |
The atmospheric CO2 records were sourced from the US National Oceanographic and Atmospheric Administration’s Earth System Research Laboratory and relate to concentrations measured at their Mauna Loa station in Hawaii. The Global Average Surface Temperature records were sourced from the Earth Policy Institute, based on data from NASA’s Goddard Institute for Space Studies and relate to measurements from the latter’s Global Historical Climatology Network. This exhibit is meant to be a basic illustration of how a scatter chart can be used to compare two sets of data. Obviously actual climatological research requires a somewhat more rigorous approach than the simplistic one I have employed here. |
| [7] |
Randall’s drawings are used (with permission) liberally throughout this site,Including:
and of course |
| [8] |
Waterfall Chart – Wikipedia. |
| [9] |
Open-High-Low-Close Chart – Wikipedia. |
| [10] |
Surface Chart – AnyCharts. |
![]()
Another article from peterjamesthomas.com. The home of The Data and Analytics Dictionary, The Anatomy of a Data Function and A Brief History of Databases.



















 , one of the most misunderstood,
, one of the most misunderstood, 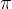 , and finally their beautiful relationship to each other
, and finally their beautiful relationship to each other 

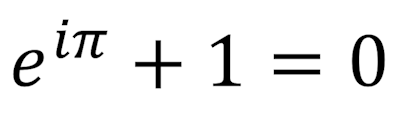


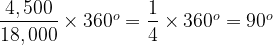
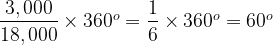




")





")
")







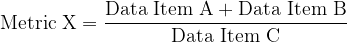
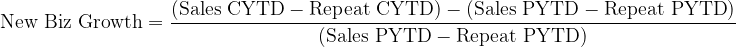



















?")