
This article draws extensively on elements of the framework I use to both highlight and manage risks on data programmes. It has its genesis in work that I did early in 2012 (but draws on experience from the years before this). I have tried to refresh the content since then to reflect new thinking and new developments in the data arena.
Introduction
What are my motivations in publishing this article? Well I have both designed and implemented data and information programmes for over 17 years. In the majority of cases my programme work has been a case of executing a data strategy that I had developed myself [1]. While I have generally been able to steer these programmes to a successful outcome [2], there have been both bumps in the road and the occasional blind alley, requiring a U-turn and another direction to be selected. I have also been able to observe data programmes that ran in parallel to mine in different parts of various organisations. Finally, I have often been asked to come in and address issues with an existing data programme; something that appears to happens all too often. In short I have seen a lot of what works and what does not work. Having also run other types of programmes [3], I can also attest to data programmes being different. Failure to recognise this difference and thus approaching a data programme just like any other piece of work is one major cause of issues [4].
Before I get into my list proper, I wanted to pause to highlight a further couple of mistakes that I have seen made more than once; ones that are more generic in nature and thus don’t appear on my list of 20 risks. The first is to assume that the way that an organisation’s data is controlled and leveraged can be improved in a sustainable way by just kicking off a programme. What is more important in my experience is to establish a data function, which will then help with both the governance and exploitation of data. This data function, ideally sitting under a CDO, will of course want to initiate a range of projects, from improving data quality, to sprucing up reporting, to establishing better analytical capabilities. Best practice is to gather these activities into a programme, but things work best if the data function is established first, owns such a programme and actively partakes in its execution.

As well as the issue of ongoing versus transitory accountability for data and the undoubted damage that poorly coordinated change programmes can inflict on data assets, another driver for first establishing a data function is that data needs will always be there. On the governance side, new systems will be built, bought and integrated, bringing new data challenges. On the analytical side, there will always be new questions to be answered, or old ones to be reevaluated. While data-centric efforts will generate many projects with start and end dates, the broad stream of data work continues on in a way that, for example, the implementation of a new B2C capability does not.
The second is to believe that you will add lasting value by outsourcing anything but targeted elements of your data programme. This is not to say that there is no place for such arrangements, which I have used myself many times, just that one of the lasting benefits of gimlet-like focus on data is the IP that is built up in the data team; IP that in my experience can be leveraged in many different and beneficial ways, becoming a major asset to the organisation [5].
Having made these introductory comments, let’s get on to the main list, which is divided into broadly chronological sections, relating to stages of the programme. The 10 risks which I believe are either most likely to materialise, or which will probably have the greatest impact are highlighted in pale yellow.
Up-front Risks

| Risk |
Potential Impact |
| 1. |
Not appreciating the size of work for both business and technology resources. |
Team is set up to fail – it is neither responsive enough to business needs (resulting in yet more “unofficial” repositories and additional fragmentation), nor is appropriate progress is made on its central objective. |
| 2. |
Not establishing a dedicated team. |
The team never escapes from “the day job” or legacy / BAU issues; the past prevents the future from being built. |
| 3. |
Not establishing a unified and collaborative team. |
Team is plagued by people pursuing their own agendas and trashing other people’s approaches, this consumes management time on non-value-added activities, leads to infighting and dissipates energy. |
| 4. |
Staff lack skills and prior experience of data programmes. |
Time spent educating people rather than getting on with work. Sub-optimal functionality, slippages, later performance problems, higher ongoing support costs. |
| 5. |
Not establishing an appropriate management / governance structure. |
Programme is not aligned with business needs, is not able to get necessary time with business users and cannot negotiate the inevitable obstacles that block its way. As a result, the programme gets “stuck in the mud”. |
| 6. |
Failing to recognise ongoing local needs when centralising. |
Local business units do not have their pressing needs attended to and so lose confidence in the programme and instead go their own way. This leads to duplication of effort, increased costs and likely programme failure. |
With risk 2 an analogy is trying to build a house in your spare time. If work can only be done in evenings or at the weekend, then this is going to take a long time. Nevertheless organisations too frequently expect data programmes to be absorbed in existing headcount and fitted in between people’s day jobs.
We can we extend the building metaphor to cover risk 4. If you are going to build your own house, it would help that you understand carpentry, plumbing, electricals and brick-laying and also have a grasp on the design fundamentals of how to create a structure that will withstand wind rain and snow. Too often companies embark on data programmes with staff who have a bit of a background in reporting or some related area and with managers who have never been involved in a data programme before. This is clearly a recipe for disaster.
Risk 5 reminds us that governance is also important – both to ensure that the programme stays focussed on business needs and also to help the team to negotiate the inevitable obstacles. This comes back to a successful data programme needing to be more than just a technology project.
Programme Execution Risks

| Risk |
Potential Impact |
| 7. |
Poor programme management. |
The programme loses direction. Time is expended on non-core issues. Milestones are missed. Expenditure escalates beyond budget. |
| 8. |
Poor programme communication. |
Stakeholders have no idea what is happening [6]. The programme is viewed as out of touch / not pertinent to business issues. Steering does not understand what is being done or why. Prospective users have no interest in the programme. |
| 9. |
Big Bang approach. |
Too much time goes by without any value being created. The eventual Big Bang is instead a damp squib. Large sums of money are spent without any benefits. |
| 10. |
Endless search for the perfect solution / adherence to overly theoretical approaches. |
Programme constantly polishes rocks rather than delivering. Data models reflect academic purity rather than real-world performance and maintenance needs. |
| 11. |
Lack of focus on interim deliverables. |
Business units become frustrated and seek alternative ways to meet their pressing needs. This leads to greater fragmentation and reputational damage to programme. |
| 12. |
Insufficient time spent understanding source system data and how data is transformed as it flows between systems. |
Data capabilities that do not reflect business transactions with fidelity. There is inconsistency with reports directly drawn from source systems. Reconciliation issues arise (see next point). |
| 13. |
Poor reconciliation. |
If analytical capabilities do not tell a consistent story, they will not be credible and will not be used. |
| 14. |
Strong approach to data quality. |
Data facilities are seen as inaccurate because of poor data going into them. Data facilities do not match actual business events due to either massaging of data or exclusion of transactions with invalid attributes. |
Probably the single most common cause of failure with data programmes – and indeed or ERP projects and acquisitions and any other type of complex endeavour – is risk 7, poor programme management. Not only do programme managers have to be competent, they should also be steeped in data matters and have a good grasp of the factors that differentiate data programmes from more general work.
Relating to the other highlighted risks in this section, the programme could spend two years doing work without surfacing anything much and then, when they do make their first delivery, this is a dismal failure. In the same vein, exclusive focus on strategic capabilities could prevent attention being paid to pressing business needs. At the other end of the spectrum, interim deliveries could spiral out of control, consuming all of the data team’s time and meaning that the strategic objective is never reached. A better approach is that targeted and prioritised interims help to address pressing business needs, but also inform more strategic work. From the other perspective, progress on strategic work-streams should be leveraged whenever it can be, perhaps in less functional manners that the eventual solution, but good enough and also helping to make sure that the final deliveries are spot on [7].
User Requirement Risks

| Risk |
Potential Impact |
| 15. |
Not enough up-front focus on understanding key business decisions and the information necessary to take them. |
Analytic capabilities do not focus on what people want or need, leading to poor adoption and benefits not being achieved. |
| 16. |
In the absence of the above, the programme becoming a technology-driven one. |
The business gets what IT or Change think that they need, not what is actually needed. There is more focus on shiny toys than on actionable information. The programme forgets the needs of its customers. |
| 17. |
A focus on replicating what the organisation already has but in better tools, rather than creating what it wants. |
Beautiful data visualisations that tell you close to nothing. Long lists of existing reports with their fields cross-referenced to each other and a new solution that is essentially the lowest common denominator of what is already in place; a step backwards. |
The other most common reasons for data programme failure is a lack of focus on user needs and insufficient time spent with business people to ensure that systems reflect their requirements [8].
Integration Risk

| Risk |
Potential Impact |
| 18. |
Lack of leverage of new data capabilities in front-end / digital systems. |
These systems are less effective. The data team is jealous about its capabilities being the only way that users should get information, rather than adopting a more pragmatic and value-added approach. |
It is important for the data team to realise that their work, however important, is just one part of driving a business forward. Opportunities to improve other system facilities by the leverage of new data structures should be taken wherever possible.
Deployment Risks

| Risk |
Potential Impact |
| 19. |
Education is an afterthought, training is technology- rather than business-focused. |
People neither understand the capabilities of new analytical tools, nor how to use them to derive business value. Again this leads to poor adoption and little return on investment. |
| 20. |
Declaring success after initial implementation and training. |
Without continuing to water the immature roots, the plant withers. Early adoption rates fall and people return to how they were getting information pre-launch. This means that the benefits of the programme not realised. |
Finally excellent technical work needs to be complemented with equal attention to business-focussed education, training using real-life scenarios and assiduous follow up. These things will make or break the programme [9].
Summary.
Of course I don’t claim that the above list is exhaustive. You could successfully mitigate all of the above risks on your data programme, but still get sunk by some other unforeseen problem arising. There is a need to be flexible and to adapt to both events and how your organisation operates; there are no guarantees and no foolproof recipes for success [10].
My recommendation to data professionals is to develop your own approach to risk management based on your own experience, your own style and the culture within which you are operating. If just a few of the items on my list of risks can be usefully amalgamated into this, then I will feel that this article has served its purpose. If you are embarking on a data programme, maybe your first one, then be warned that these are hard and your reserves of perseverance will be tested. I’d suggest leveraging whatever tools you can find in trying to forge ahead.
It is also maybe worth noting that, somewhat contrary to my point that data programmes are different, a few of the risks that I highlight above could be tweaked to apply to more general programmes as well. Hopefully the things that I have learnt over the last couple of decades of running data programmes will be something that can be of assistance to you in your own work.
Notes


")
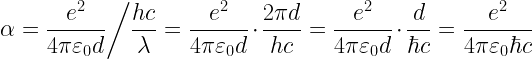

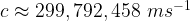
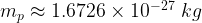
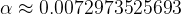 – which doesn’t have a unit (it’s dimensionless)
– which doesn’t have a unit (it’s dimensionless)






























?")



















")

