")
Similar to its predecessor, Why are so many businesses still doing a poor job of managing data in 2019? this brief article has its genesis in the question that appears in its title, something that I was asked to opine on recently. Here is an expanded version of what I wrote in reply:
Well the first part of the answer is based on consideing activities which have at least moderate difficulty and complexity associated with them. The majority of such activities that humans attempt will end in failure. Indeed I think that the oft-reported failure rate, which is in the range 60 – 70%, is probably a fundamental Physical constant; just like the speed of light in a vacuum [1], the rest mass of a proton [2], or the fine structure constant [3].
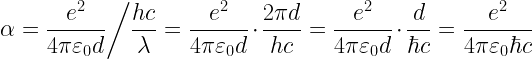
For more on this, see the preambles to both Ever tried? Ever failed? and Ideas for avoiding Big Data failures and for dealing with them if they happen.
Beyond that, what I have seen a lot is Data Migration being the poor relation of programme work-streams. Maybe the overall programme is to implement a new Transaction Platform, integrated with a new Digital front-end; this will replace 5+ legacy systems. When the programme starts the charter says that five years of history will be migrated from the 5+ systems that are being decommissioned.

Then the costs of the programme escallate [4] and something has to give to stay on budget. At the same time, when people who actually understand data make a proper assessment of the amount of work required to consolidate and conform the 5+ disparate data sets, it is found that the initial estimate for this work [5] was woefully inadequate. The combination leads to a change in migration scope, just two years historical data will now be migrated.
Rinse and repeat…
The latest strategy is to not migrate any data, but instead get the existing data team to build a Repository that will allow users to query historical data from the 5+ systems to be decommissioned. This task will fall under BAU [6] activities (thus getting programme expenditure back on track).
The slight flaw here is that building such a Repository is essentially a big chunk of the effort required for Data Migration and – of course – the BAU budget will not be enough for this quantum work. Oh well, someone else’s problem, the programme budget suddenly looks much rosier, only 20% over budget now…
Note: I may have exaggerated a bit to make a point, but in all honesty, not really by that much.
Notes
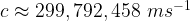
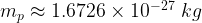
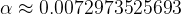 – which doesn’t have a unit (it’s dimensionless)
– which doesn’t have a unit (it’s dimensionless)
![]()
Another article from peterjamesthomas.com. The home of The Data and Analytics Dictionary, The Anatomy of a Data Function and A Brief History of Databases.
