When I occasionally re-read articles I penned back in 2009 or 2010, I’m often struck that – no matter how many things have undeniably changed over the intervening years in the data arena – there are some seemingly eternal verities. For example, it’s never just about the technology and indeed it’s seldom even predominantly about the technology [1]. True then, true now. These articles have a certain timeless quality to them. This is not that sort of article…
This is an article written at a certain time and in certain circumstances. I fervently hope that it rapidly becomes an anachronism.
Here and now, in late March 2020, many of us are adjusting to working from home for the first time on an extended basis [2]. In talking to friends and associates, this can be a difficult transition. Humans are inherently social animals and limiting our social interactions can be injurious to mental health. Fortunately, people also seem to be coming up with creative ways to stay in touch and the array of tools at our disposal to do this has never been greater.
In this piece, I wanted to talk about my first experience of extended home working. In my last article, Data Strategy Creation – A Roadmap, I hopefully gave some sense of the complexities involved in developing a commercially focussed Data Strategy. Well my task while home working for the first time was to do just that!
Back then, I ended up being successful without the benefit of more modern communications facilities, which is hopefully a helpful to learn for people today. Not only can you get by when working from home, you can take on some types of complicated work and do it well.
To provide some more colour, let’s go back to 2007 / 2008. Even in the midst of what was then obviously the Dark Ages, we did have email and even the Internet, but to be honest the “revolutionary” technology I used most often was well over a hundred years old at that point, let me introduce you to it…

First some context. I had successfully developed and then executed a Data Strategy for the European operations of a leading Global General Insurer. This work had played a pivotal role in returning the organisation to profitability following record losses. On the back of this, I was promoted to also be accountable for Data across the organisation’s businesses in Asia / Pacific, Canada and Latin America. The span of my new responsibilities is shown further down the page.
My first task was to develop an International Data Strategy. As per the framework that I began to develop as part of this assignment, I needed to speak to a lot of people, both business and technical. I needed to understand what was different about Insurance Markets as diverse as China and Brasil. I needed to understand a systems and data landscape spanning five continents. And – importantly – I needed to establish and then build on personal relationships with a lot of different people from different cultures in different locations. There was also the minor issue of time zones to be dealt with. Then I like a challenge.

My transition to home working in this role was not driven by the type of deadly pathogen that we currently face, but by more quotidian considerations. The work I was initially doing primarily related to the activities tagged as 1.3 Business Interviews and 1.5 Technical Staff Discussions in my Data Strategy framework. Relative to this, I found that I was speaking to Singapore (where there was a team of data developers as well as several stakeholders) at 6am or even earlier; seguing to my continuing European responsibilities not long after; then had Latin and North America come on stream in the afternoon, going through until late; and sometimes picking things up with Australia or Asia Pacific locations at 11pm or midnight.
I was often writing up notes straight after meetings, or comparing them to previous ones looking for commonalities and teasing out themes. Because of this, there was not a lot of time for a commute to central London. Equally as I was on the ‘phone or email all of the time, there was little need for me to go into the office. So working from home became my “new normal”.
I could of course go into the office if I wanted to. It was also possible to go out and have a meal with my wife. Finally, I was not worried about getting sick or this happening to my family. So things were not so difficult as they are today. It did however take me some time to adjust to these different arrangements. One thing I learnt was that I couldn’t work solidly every day from 6am to midnight – an amazing revelation I realise. Given the extended nature of my day, I had to build breaks in.

As I was working well in excess of my contractual hours, if a gap opened up in my day, I would do things like cycle to Regent’s Park and do laps of the outer circle. A major activity for me at the time was rock climbing and so I would take a break and work out on a training aid called a fingerboard, which we had two of (see above). Trying to hang from this by two fingers tended to clear the mind.
To return to the work, there were elements of this that blunted any feeling of isolation. Of course I ran my notes past the people interviewed, a second point of interaction. I also found a handful of people in each territory who were very positive about driving change through enhanced information. With these I held ongoing chats, discussing the views of their colleagues, contrasting these to those of other people around the organisation, sharing preliminary findings and nascent ideas for moving forward, getting their feedback on all of this. As well as helping me to have sounding boards for my ideas and getting alternative input, this was also great for building relationships; something that is harder over the ‘phone, but – as I found – far from impossible. However, it did require effort and, importantly, that effort needed to be sustained.
Something I thankfully figured out quite early was that email was not enough. Even with busy people on the other side of the world, perhaps particularly with busy people on the other side of the world, it was worth arranging time to talk. Despite the efficiency and convenience of email, I made a point of also speaking and of religiously rearranging any chats that fell through. Sometimes I wanted to just drop a colleague an email, but I tried to resist the temptation. In retrospect I think this approach helped a lot – on both ends of the ‘phone line.
Over time my work gradually shifted from gathering data to analysing and synthesising it, that is figuring out what the elements of the Data Strategy should be, for example current and future states. This is never an abrupt change, you start to analyse as soon as you have done a handful of interviews, but this work ramps up as more and more interviews are ticked off. Another thing that I found was, rather than sending people a whole slide deck and inviting comments, sharing one slide / exhibit at a time worked better. That way you assemble a deck out of agreed components and also have further opportunities for telephone interaction. If you are careful enough with structuring your individual slides, then the overall story can take care of itself, or at least require minimal “connective tissue” to be woven around it.
I won’t go into every aspect of this Data Strategy work, as the point of this article is instead to focus on the working from home element. However it is worth summarising the eventual number of interviews I held and documented:

I have no idea how many ‘phone calls that equated to, but it must have been an awful lot. Most of these were carried out over the initial three-month period, with a few stragglers picked up later in parallel with rounding out the Data Strategy. The whole exercise consumed a little under six months, with the back of the work broken in slightly more than four.
In closing, the Data Strategy I developed was adopted and the international data architecture that was later rolled out remains in place today; a testament to both the work done by the development teams, but also – I hope – to my vision. Since then, I have carried out a number of similar international exercises, though not always with the working from home component. I found the lessons I learned in that initial period invaluable. For example, I use many of the the approaches I developed in 2007 / 2008 in my work today as well.
So the closing message is that things are obviously far from normal right now. But – as challenging as working from home may seem – it is possible to be productive and also to lift your eyes above keeping the business running in order to contemplate more complicated transformation activities. I hope that this knowledge is of some help to those grappling, as I did years ago, with “the new normal”.
If – despite current circumstances – you need to develop a Data Strategy and would like some help, then please get in contact via the form provided. You can also speak to us on +44 (0) 20 8895 6826.
Notes
[1] |
To see why, consider reading A bad workman blames his [Business Intelligence] tools. |
[2] |
I of course appreciate that many people do not have this option due to the type of work that they do. I also appreciate that many unfortunate people will have no work in current circumstances. |

Another article from peterjamesthomas.com. The home of The Data and Analytics Dictionary, The Anatomy of a Data Function and A Brief History of Databases.

")

 The author, working from home together with his Executive Assistant
The author, working from home together with his Executive Assistant

 The author, engaged in measuring maturity – ©
The author, engaged in measuring maturity – © 




")
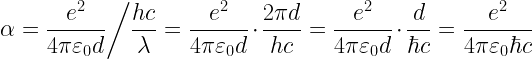

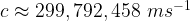
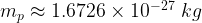
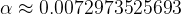 – which doesn’t have a unit (it’s dimensionless)
– which doesn’t have a unit (it’s dimensionless)
