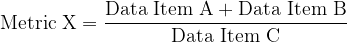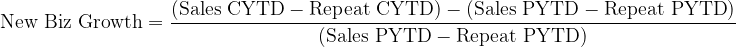This article is about facts. Facts are sometimes less solid than we would like to think; sometimes they are downright malleable. To illustrate, consider the fact that in 98 episodes of Dragnet, Sergeant Joe Friday never uttered the words “Just the facts Ma’am”, though he did often employ the variant alluded to in the image above [1]. Equally, Rick never said “Play it again Sam” in Casablanca [2] and St. Paul never suggested that “money is the root of all evil” [3]. As Michael Caine never said in any film, “not a lot of people know that” [4].
Fact-based decision making. It sounds good doesn’t it? Especially if you consider the alternatives: going on gut feel, doing what you did last time, guessing, not taking a decision at all. However – as is often the case with issues I deal with on this blog – fact-based decision-making is easier to say than it is to achieve. Here I will look to cover some of the obstacles and suggest a potential way to navigate round them. Let’s start however with some definitions.
So one can infer that fact-based decision-making is the process of reaching a conclusion based on consideration of things that are known to be true. Again, it sounds great doesn’t it? It seems that all you have to do is to find things that are true. How hard can that be? Well actually quite hard as it happens. Let’s cover what can go wrong (note: this section is not intended to be exhaustive, links are provided to more in-depth articles where appropriate):
Accuracy of Data that is captured

A number of factors can play into the accuracy of data capture. Some systems (even in 2018) can still make it harder to capture good data than to ram in bad. Often an issue may also be a lack of master data definitions, so that similar data is labelled differently in different systems.
A more pernicious problem is combinatorial data accuracy, two data items are both valid, but not in combination with each other. However, often the biggest stumbling block is a human one, getting people to buy in to the idea that the care and attention they pay to data capture will pay dividends later in the process.
These and other areas are covered in greater detail in an older article, Using BI to drive improvements in data quality.
Honesty of Data that is captured

Data may be perfectly valid, but still not represent reality. Here I’ll let Neil Raden point out the central issue in his customary style:
People find the most ingenious ways to distort measurement systems to generate the numbers that are desired, not only NOT providing the desired behaviors, but often becoming more dysfunctional through the effort.
[…] voluntary compliance to the [US] tax code encourages a national obsession with “loopholes”, and what salesman hasn’t “sandbagged” a few deals for next quarter after she has met her quota for the current one?
Where there is a reward to be gained or a punishment to be avoided, by hitting certain numbers in a certain way, the creativeness of humans often comes to the fore. It is hard to account for such tweaking in measurement systems.
Timing issues with Data

Timing is often problematic. For example, a transaction completed near the end of a period gets recorded in the next period instead, one early in a new period goes into the prior period, which is still open. There is also (as referenced by Neil in his comments above) the delayed booking of transactions in order to – with the nicest possible description – smooth revenues. It is not just hypothetical salespeople who do this of course. Entire organisations can make smoothing adjustments to their figures before publishing and deferral or expedition of obligations and earnings has become something of an art form in accounting circles. While no doubt most of this tweaking is done with the best intentions, it can compromise the fact-based approach that we are aiming for.
Reliability with which Data is moved around and consolidated

In our modern architectures, replete with web-services, APIs, cloud-based components and the quasi-instantaneous transmission of new transactions, it is perhaps not surprising that occasionally some data gets lost in translation [5] along the way. That is before data starts to be Sqooped up into Data Lakes, or other such Data Repositories, and then otherwise manipulated in order to derive insight or provide regular information. All of these are processes which can introduce their own errors. Suffice it to say that transmission, collation and manipulation of data can all reduce its accuracy.
Again see Using BI to drive improvements in data quality for further details.
Pertinence and fidelity of metrics developed from Data

Here we get past issues with data itself (or how it is handled and moved around) and instead consider how it is used. Metrics are seldom reliant on just one data element, but are often rather combinations. The different elements might come in because a given metric is arithmetical in nature, e.g.
Choices are made as to how to construct such compound metrics and how to relate them to actual business outcomes. For example:
Is this a good way to define New Business Growth? Are there any weaknesses in this definition, for example is it sensitive to any glitches in – say – the tagging of Repeat Business? Do we need to take account of pricing changes between Repeat Business this year and last year? Is New Business Growth something that is even worth tracking; what will we do as a result of understanding this?
The above is a somewhat simple metric, in a section of Using historical data to justify BI investments – Part I, I cover some actual Insurance industry metrics that build on each other and are a little more convoluted. The same article also considers how to – amongst other things – match revenue and outgoings when the latter are spread over time. There are often compromises to be made in defining metrics. Some of these are based on the data available. Some relate to inherent issues with what is being measured. In other cases, a metric may be a best approximation to some indication of business health; a proxy used because that indication is not directly measurable itself. In the last case, staff turnover may be a proxy for staff morale, but it does not directly measure how employees are feeling (a competitor might be poaching otherwise happy staff for example).
Robustness of extrapolations made from Data

I have used the above image before in these pages [6]. The situation it describes may seem farcical, but it is actually not too far away from some extrapolations I have seen in a business context. For example, a prediction of full-year sales may consist of this year’s figures for the first three quarters supplemented by prior year sales for the final quarter. While our metric may be better than nothing, there are some potential distortions related to such an approach:
- Repeat business may have fallen into Q4 last year, but was processed in Q3 this year. This shift in timing would lead to such business being double-counted in our year end estimate.
- Taking point 1 to one side, sales may be growing or contracting compared to the previous year. Using Q4 prior year as is would not reflect this.
- It is entirely feasible that some market event occurs this year ( for example the entrance or exit of a competitor, or the launch of a new competitor product) which would render prior year figures a poor guide.
Of course all of the above can be adjusted for, but such adjustments would be reliant on human judgement, making any projections similarly reliant on people’s opinions (which as Neil points out may be influenced, conciously or unconsciously, by self-interest). Where sales are based on conversions of prospects, the quantum of prospects might be a more useful predictor of Q4 sales. However here a historical conversion rate would need to be calculated (or conversion probabilities allocated by the salespeople involved) and we are back into essentially the same issues as catalogued above.
I explore some similar themes in a section of Data Visualisation – A Scientific Treatment
Integrity of statistical estimates based on Data

Having spent 18 years working in various parts of the Insurance industry, statistical estimates being part of the standard set of metrics is pretty familiar to me [7]. However such estimates appear in a number of industries, sometimes explicitly, sometimes implicitly. A clear parallel would be credit risk in Retail Banking, but something as simple as an estimate of potentially delinquent debtors is an inherently statistical figure (albeit one that may not depend on the output of a statistical model).
The thing with statistical estimates is that they are never a single figure but a range. A model may for example spit out a figure like £12.4 million ± £0.5 million. Let’s unpack this.

Well the output of the model will probably be something analogous to the above image. Here a distribution has been fitted to the business event being modelled. The central point of this (the one most likely to occur according to the model) is £12.4 million. The model is not saying that £12.4 million is the answer, it is saying it is the central point of a range of potential figures. We typically next select a symmetrical range above and below the central figure such that we cover a high proportion of the possible outcomes for the figure being modelled; 95% of them is typical [8]. In the above example, the range extends plus £0. 5 million above £12.4 million and £0.5 million below it (hence the ± sign).
Of course the problem is then that Financial Reports (or indeed most Management Reports) are not set up to cope with plus or minus figures, so typically one of £12.4 million (the central prediction) or £11.9 million (the most conservative estimate [9]) is used. The fact that the number itself is uncertain can get lost along the way. By the time that people who need to take decisions based on such information are in the loop, the inherent uncertainty of the prediction may have disappeared. This can be problematic. Suppose a real result of £12.4 million sees an organisation breaking even, but one of £11.9 million sees a small loss being recorded. This could have quite an influence on what course of action managers adopt [10]; are they relaxed, or concerned?
Beyond the above, it is not exactly unheard of for statistical models to have glitches, sometimes quite big glitches [11].
This segment could easily expand into a series of articles itself. Hopefully I have covered enough to highlight that there may be some challenges in this area.
And so what?

Even if we somehow avoid all of the above pitfalls, there remains one booby-trap that is likely to snare us, absent the necessary diligence. This was alluded to in the section about the definition of metrics:
Is New Business Growth something that is even worth tracking; what will we do as a result of understanding this?
Unless a reported figure, or output of a model, leads to action being taken, it is essentially useless. Facts that never lead to anyone doing anything are like lists learnt by rote at school and regurgitated on demand parrot-fashion; they demonstrate the mechanism of memory, but not that of understanding. As Neil puts it in his article:
[…] technology is never a solution to social problems, and interactions between human beings are inherently social. This is why performance management is a very complex discipline, not just the implementation of dashboard or scorecard technology.
How to Measure the Unmeasurable

Our dream of fact-based decision-making seems to be crumbling to dust. Regular facts are subject to data quality issues, or manipulation by creative humans. As data is moved from system to system and repository to repository, the facts can sometimes acquire an “alt-” prefix. Timing issues and the design of metrics can also erode accuracy. Then there are many perils and pitfalls associated with simple extrapolation and less simple statistical models. Finally, any fact that manages to emerge from this gantlet [12] unscathed may then be totally ignored by those whose actions it is meant to guide. What can be done?
As happens elsewhere on this site, let me turn to another field for inspiration. Not for the first time, let’s consider what Science can teach us about dealing with such issues with facts. In a recent article [13] in my Maths & Science section, I examined the nature of Scientific Theory and – in particular – explored the imprecision inherent in the Scientific Method. Here is some of what I wrote:
It is part of the nature of scientific theories that (unlike their Mathematical namesakes) they are not “true” and indeed do not seek to be “true”. They are models that seek to describe reality, but which often fall short of this aim in certain circumstances. General Relativity matches observed facts to a greater degree than Newtonian Gravity, but this does not mean that General Relativity is “true”, there may be some other, more refined, theory that explains everything that General Relativity does, but which goes on to explain things that it does not. This new theory may match reality in cases where General Relativity does not. This is the essence of the Scientific Method, never satisfied, always seeking to expand or improve existing thought.
I think that the Scientific Method that has served humanity so well over the centuries is applicable to our business dilemma. In the same way that a Scientific Theory is never “true”, but instead useful for explaining observations and predicting the unobserved, business metrics should be judged less on their veracity (though it would be nice if they bore some relation to reality) and instead on how often they lead to the right action being taken and the wrong action being avoided. This is an argument for metrics to be simple to understand and tied to how decision-makers actually think, rather than some other more abstruse and theoretical definition.
A proxy metric is fine, so long as it yields the right result (and the right behaviour) more often than not. A metric with dubious data quality is still useful if it points in the right direction; if the compass needle is no more than a few degrees out. While of course steps that improve the accuracy of metrics are valuable and should be undertaken where cost-effective, at least equal attention should be paid to ensuring that – when the metric has been accessed and digested – something happens as a result. This latter goal is a long way from the arcana of data lineage and metric definition, it is instead the province of human psychology; something that the accomploished data professional should be adept at influencing.
I have touched on how to positively modify human behaviour in these pages a number of times before [14]. It is a subject that I will be coming back to again in coming months, so please watch this space.
Further reading on this subject:
Notes
[1] |
According to Snopes, the phrase arose from a spoof of the series. |
[2] |
The two pertinent exchanges were instead:
| Ilsa: |
Play it once, Sam. For old times’ sake. |
| Sam: |
I don’t know what you mean, Miss Ilsa. |
| Ilsa: |
Play it, Sam. Play “As Time Goes By” |
| Sam: |
Oh, I can’t remember it, Miss Ilsa. I’m a little rusty on it. |
| Ilsa: |
I’ll hum it for you. Da-dy-da-dy-da-dum, da-dy-da-dee-da-dum… |
| Ilsa: |
Sing it, Sam. |
and
| Rick: |
You know what I want to hear. |
| Sam: |
No, I don’t. |
| Rick: |
You played it for her, you can play it for me! |
| Sam: |
Well, I don’t think I can remember… |
| Rick: |
If she can stand it, I can! Play it! |
|
[3] |
Though he, or whoever may have written the first epistle to Timothy, might have condemned the “love of money”. |
[4] |
The origin of this was a Peter Sellers interview in which he impersonated Caine. |
[5] |
One of my Top Ten films. |
[6] |
Especially for all Business Analytics professionals out there (2009). |
[7] |
See in particular my trilogy:
- Using historical data to justify BI investments – Part I (2011)
- Using historical data to justify BI investments – Part II (2011)
- Using historical data to justify BI investments – Part III (2011)
|
[8] |
Without getting into too many details, what you are typically doing is stating that there is a less than 5% chance that the measurements forming model input match the distribution due to a fluke; but this is not meant to be a primer on null hypotheses. |
[9] |
Of course, depending on context, £12.9 million could instead be the most conservative estimate. |
[10] |
This happens a lot in election polling. Candidate A may be estimated to be 3 points ahead of Candidate B, but with an error margin of 5 points, it should be no real surprise when Candidate B wins the ballot. |
[11] |
Try googling Nobel Laureates Myron Scholes and Robert Merton and then look for references to Long-term Capital Management. |
[12] |
Yes I meant “gantlet” that is the word in the original phrase, not “gauntlet” and so connections with gloves are wide of the mark. |
[13] |
Finches, Feathers and Apples (2018). |
[14] |
For example:
|
From: peterjamesthomas.com, home of The Data and Analytics Dictionary, The Anatomy of a Data Function and A Brief History of Databases



 , one of the most misunderstood,
, one of the most misunderstood,  , and finally their beautiful relationship to each other
, and finally their beautiful relationship to each other 

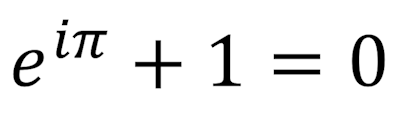

")










")






")
")