
This Fox has a longing for grapes:
He jumps, but the bunch still escapes.
So he goes away sour;
And, ’tis said, to this hour
Declares that he’s no taste for grapes.
— W.J.Linton (after Aesop)
| Note:
Not all of the organisations I have worked with or for have had a C-level Executive accountable primarily for Marketing. Where they have, I have normally found the people holding these roles to be better informed about data matters than their peers. I have always found it easy and enjoyable to collaborate with such people. The same goes in general for Marketing Managers. This article is not about Marketing professionals, it is about poorly researched journalism. |
Prelude…

I recently came across an article in Marketing Week with the clickbait-worthy headline of Why the rise of the chief data officer will be short-lived (their choice of capitalisation). The subhead continues in the same vein:
Chief data officers (ditto) are becoming increasingly common, but for a data strategy to work their appointments can only ever be a temporary fix.
Intrigued, I felt I had to avail myself of the wisdom and domain expertise contained in the article (the clickbait worked of course). The first few paragraphs reveal the actual motivation. The piece is a reaction [1] to the most senior Marketing person at easyJet being moved out of his role, which is being abolished, and – as part of the same reorganisation – a Chief Data Officer (CDO) being appointed. Now the first thing to say, based on the article’s introductory comments, is that easyJet did not have a Chief Marketing Officer. The role that was abolished was instead Chief Commercial Officer, so there was no one charged full-time with Marketing anyway. The Marketing responsibilities previously supported part-time by the CCO have now been spread among other executives.
The next part of the article covers the views of a Marketing Week columnist (pause for irony) before moving on to arrangements for the management of data matters in three UK-based organisations:
- Camelot – who run the UK National Lottery
- Mumsnet – which is a web-site for UK parents
- Flubit – a growing on-line marketplace aiming to compete with Amazon
The first two of these have CDOs (albeit with one doing the role alongside other responsibilities). Both of these people:
[…] come at data as people with backgrounds in its use in marketing
Flubit does not have a CDO, which is used as supporting evidence for the superfluous nature of the role [2].
Suffice it to say that a straw poll consisting of the handful of organisations that the journalist was able to get a comment from is not the most robust of approaches [3]. Most of the time, the article does nothing more than to reflect the continuing confusion about whether or not organisations need CDOs and – assuming that they do – what their remit should be and who they should report to [4].
But then, without it has to be said much supporting evidence, the piece goes on to add that:
Most [CDOs – they would probably style it “Cdos”] are brought in to instill a data strategy across the business; once that is done their role should no longer be needed.

Now as a Group Theoretician, I am a great fan of symmetry. Symmetry relates to properties that remain invariant when something else is changed. Archetypally, an equilateral triangle is still an equilateral triangle when rotated by 120° [5]. More concretely, the laws of motion work just fine if we wind the clock forward 10 seconds (which incidentally leads to the principle of conservation of energy [6]).
Let’s assume that the Marketing Week assertion is true. I claim therefore that it must be still be true under the symmetry of changing the C-level role. This would mean that the following also has to be true:
Most [Chief marketing officers] are brought in to instill a marketing strategy across the business; once that is done their role should no longer be needed.
Now maybe this statement is indeed true. However, I can’t really see the guys and gals at Marketing Week agreeing with this. So maybe it’s false instead. Then – employing reductio ad absurdum – the initial statement is also false [7].
If you don’t work in Marketing, then maybe a further transformation will convince you:
Most [Chief financial officers] are brought in to instill a finance strategy across the business; once that is done their role should no longer be needed.
I could go on, but this is already becoming as tedious to write as it was to read the original Marketing Week claim. The closing sentence of the article is probably its most revealing and informative:
[…] marketers must make sure they are leading [the data] agenda, or someone else will do it for them.
I will leave readers to draw their own conclusions on the merits of this piece and move on to other thoughts that reading it spurred in me.
…and Fugue

Sometimes buried in the strangest of places you can find something of value, even if the value is different to the intentions of the person who buried it. Around some of the CDO forums that I attend [8] there is occasionally talk about just the type of issue that Marketing Week raises. An historical role often comes up in these discussions is that of Chief Electrification Officer [9]. This supposedly was an Executive role in organisations as the 19th Century turned into the 20th and electricity grids began to be created. The person ostensibly filling this role would be responsible for shepherding the organisation’s transition from earlier forms of power (e.g. steam) to the new-fangled streams of electrons. Of course this role would be very important until the transition was completed, after that redundancy surely beckoned.
Well to my way of thinking, there are a couple of problems here. The first one of these is alluded to by my choice of the words “supposedly” and “ostensibly” above. I am not entirely sure, based on my initial research [10], that this role ever actually existed. All the references I can find to it are modern pieces comparing it to the CDO role, so perhaps it is apochryphal.
The second is somewhat related. Electrification was an engineering problem, indeed it the [US] National Academy of Engineering called it “the greatest engineering achievement of the 20th Century”. Surely the people tackling this would be engineers, potentially led by a Chief Engineer. Did the completion of electrification mean that there was no longer a need for engineers, or did they simply move on to the next engineering problem [11]?
Extending this analogy, I think that Chief Data Officers are more like Chief Engineers than Chief Electrification Officers, assuming that the latter even exists. Why the confusion? Well I think part of it is because, over the last decade and a bit, organisations have been conditioned to believe the one dimensional perspective that everything is a programme or a project [12]. I am less sure that this applies 100% to the CDO role.
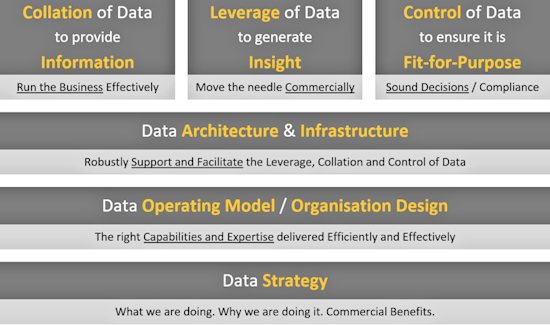
It may well be that one thing that a CDO needs to get going is a data transformation programme. This may purely be focused on cultural aspects of how an organisation records, shares and otherwise uses data. It may be to build a new (or a first) Data Architecture. It may be to remediate issues with an existing Data Architecture. It may be to introduce or expand Data Governance. It may be to improve Data Quality. Or (and, in my experience, this is often the most likely) a combination of all these five, plus other work, such as rapid tactical or interim deliveries. However, there is also a large element of data-centric work which is not project-based and instead falls into the category often described as “business as usual” (I loathe this term – I think that Data Operations & Technology is preferable). A handful of examples are as follows (this is not meant to be an exhaustive list) [13]:
- Addressing architectural debt that results from neglect of a Data Assets or the frequently deleterious impact of improperly governed change portfolios [14]. This is often a series of small to medium-sized changes, rather than a project with a discrete scope and start and end dates.
- More positively, engaging proactively in the change process in an attempt to act as a steward of Data Assets.
- Establishing a regular Data Audit.
- Regular Data Management activities.
- Providing tailored Analytics to help understand some unscheduled or unexpected event.
- Establishment of a data “SWAT team” to respond to urgent architecture, quality or reporting needs.
- Running a Data Governance committee and related activities.
- Creating and managing a Data Science capability.
- Providing help and advice to those struggling to use Data facilities.
- Responding to new Data regulations.
- Creating and maintaining a target operating model for Data and is use.
- Supporting Data Services to aid systems integration.
- Production of regular reports and refreshing self-serve Data Repositories.
- Testing and re-testing of Data facilities subject to change or change in source Data.
- Providing training in the use of Data facilities or the importance of getting Data right-first-time.
The above all point to the need for an ongoing Data Function to meet these needs (and to form the core resources of any data programme / project work). I describe such a function in my series about The Anatomy of a Data Function.

There are of course many other such examples, but instead of cataloguing each of them, let’s return to what Marketing Week describe as the central responsibility of a CDO, to formulate a Data Strategy. Surely this is a one-off activity, right?
Well is the Marketing strategy set once and then never changed? If there is some material shift in the overall Business strategy, might the Marketing strategy change as a result? What would be the impact on an existing Marketing strategy of insight showing that this was being less than effective; might this lead to the development of a new Marketing strategy? Would the Marketing strategy need to be revised to cater for new products and services, or new segments and territories? What would be the impact on the Marketing strategy of an acquisition or divestment?
As anyone who has spent significant time in the strategy arena will tell you, it is a fluid area. Things are never set in stone and strategies may need to be significantly revised or indeed abandoned and replaced with something entirely new as dictated by events. Strategy is not a fire and forget exercise, not if you want it to be relevant to your business today, as opposed to a year ago. Specifically with Data Strategy (as I explain in Building Momentum – How to begin becoming a Data-driven Organisation), I would recommend keeping it rather broad brush at the begining of its development, allowing it to be adpated based on feedback from initial interim work and thus ensuring it better meets business needs.
So expecting that a Data Strategy (or any other type of strategy) to be done and dusted, with the key strategist dispensed with, is probably rather naive.
Coda

It would be really nice to think that sorting out their Data problems and seizing their Data opportunities are things that organisations can do once and then forget about. With twenty years experience of helping organisations to become more Data-centric, often with technical matters firmly in the background, I have to disabuse people of this all too frequent misconception. To adapt the National Canine Defence League’s [15 long-lived slogan from 1978:
A Chief Data Officer is for life, not just for Christmas.
With that out of the way, I’m off to write a well-informed and insightful article about how Marketing Departments should go about their business. Wish me luck!
Notes
[1] |
I first wrote “knee-jerk reaction” and then thought that maybe I was being unkind. “When they go low, we go high” is a better maxim. Note: link opens a YouTube video. |
[2] |
I am sure that I read somewhere about the importance of the number of data points in any analysis, maybe I should ask a Data Scientist to remind me about this. |
[3] |
For a more balanced view of what real CDOs do, please take a look at my ongoing series of in-depth interviews. |
[4] |
As discussed in:
|
[5] |
See Glimpses of Symmetry, Chapter 3 – Shifting Shapes for more on the properties of equilateral triangles. |
[6] |
As demonstrated by Emmy Noether in 1915. |
[7] |
At this point I think I am meant to say “Fake news! SAD!!!” |
[8] |
The [informal] proceedings of some of these may be viewed at:
|
[9] |
Or Chief Electrical Officer, or Chief Electricity Officer.
|
[10] |
I am doing some more digging and will of course update this piece should I find the evidence that has so far been elusive.
|
[11] |
Self-driving electric cars come to mind of course. That or running a Starship.

|
[12] |
As an aside, where do Programme Managers go when (or should that be if) their Programmes finish? |
[13] |
It might be argued that some of these operational functions could be handed to IT. However, given that some elements of data functions have probably been carved out of IT in the past, this might be a retrograde step. |
[14] |
See Bumps in the Road. |
[15] |
Now Dogs Trust. |
From: peterjamesthomas.com, home of The Data and Analytics Dictionary, The Anatomy of a Data Function and A Brief History of Databases

")
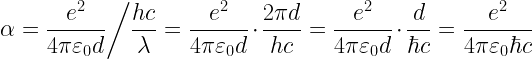

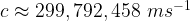
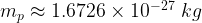
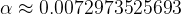 – which doesn’t have a unit (it’s dimensionless)
– which doesn’t have a unit (it’s dimensionless)









 upon a time, there was a Kingdom, the once great Kingdom of Suzerain. Of late it had fallen from its former glory and, accordingly, the King’s Chief Minister, one who saw deeper and further than most, devised a scheme which she prophesied would arrest the realm’s decline. This would entail a grand alliance with Elven artisans from beyond the Altitudinous Mountains and a tribe of journeyman Dwarves
upon a time, there was a Kingdom, the once great Kingdom of Suzerain. Of late it had fallen from its former glory and, accordingly, the King’s Chief Minister, one who saw deeper and further than most, devised a scheme which she prophesied would arrest the realm’s decline. This would entail a grand alliance with Elven artisans from beyond the Altitudinous Mountains and a tribe of journeyman Dwarves  a vision the Chief Minister saw the Kingdom’s treasury swelling. Once all was in place, the new alliances would see a fifth more gold being locked in Suzerain treasure chests before each winter solstice. Yet the King’s Chief Minister also foresaw that reaching an agreement with the Elves and Dwarves would cost much gold; there were also Suzerain smiths to be requited. Further she predicted that the Kingdom would be in turmoil for many Moons; all told three winters would come and go before the Elves and Dwarves would be working with due celerity.
a vision the Chief Minister saw the Kingdom’s treasury swelling. Once all was in place, the new alliances would see a fifth more gold being locked in Suzerain treasure chests before each winter solstice. Yet the King’s Chief Minister also foresaw that reaching an agreement with the Elves and Dwarves would cost much gold; there were also Suzerain smiths to be requited. Further she predicted that the Kingdom would be in turmoil for many Moons; all told three winters would come and go before the Elves and Dwarves would be working with due celerity. the Moon had changed, a Wizard appeared at court, from where none knew. He bore a leather bag, overspilling gold coins, in his long, delicate fingers. When the King demanded to know whence this bounty came, the Wizard stated that for five days and five nights he had surveyed Suzerain with his all-seeing-eye. This led him to discover that gold coins were being dispatched to the Goblins of the Great Arboreal Forest, gold which was not their rightful weregild
the Moon had changed, a Wizard appeared at court, from where none knew. He bore a leather bag, overspilling gold coins, in his long, delicate fingers. When the King demanded to know whence this bounty came, the Wizard stated that for five days and five nights he had surveyed Suzerain with his all-seeing-eye. This led him to discover that gold coins were being dispatched to the Goblins of the Great Arboreal Forest, gold which was not their rightful weregild  King was a wise King, but now he was gripped with uncertainty. The office of Chief Wizard commanded a stipend that was not inconsiderable. He doubted that he could both meet this and fulfil the Chief Minister’s vision. On one hand, the Wizard had shown in less than a Moon’s quarter that his thaumaturgy could yield gold from the aether. On the other, the Chief Minister’s scheme would reap dividends twofold the mage’s bounty every four seasons; but only after three winters had come and gone. The King saw that he must ponder deeply on these weighty matters and perhaps even dare to seek the counsel of his ancestors’ spirits. This would take time.
King was a wise King, but now he was gripped with uncertainty. The office of Chief Wizard commanded a stipend that was not inconsiderable. He doubted that he could both meet this and fulfil the Chief Minister’s vision. On one hand, the Wizard had shown in less than a Moon’s quarter that his thaumaturgy could yield gold from the aether. On the other, the Chief Minister’s scheme would reap dividends twofold the mage’s bounty every four seasons; but only after three winters had come and gone. The King saw that he must ponder deeply on these weighty matters and perhaps even dare to seek the counsel of his ancestors’ spirits. This would take time. it happens, the King never consulted the augurs and never decided as the Kingdom of Suzerain was totally obliterated by a marauding dragon the very next day, but the moral of the story is still crystal clear…
it happens, the King never consulted the augurs and never decided as the Kingdom of Suzerain was totally obliterated by a marauding dragon the very next day, but the moral of the story is still crystal clear…
































