The first half of my planned thoughts on Hurricanes and Data Visualisation, Rainbow’s Gravity and was published earlier back in September. Part two, Map Reading, joined it this month. In between, the first hurricane-centric article acquired an addendum, The Mona Lisa. With this post, the same has happened to the second article. Apparently you can’t keep a good hurricane story down.
One of our Hurricanes is missing
When I started writing about Hurricanes back in September of this year, it was in the aftermath of Harvey and Irma, both of which were safely far away from my native United Kingdom. Little did I think that in closing this mini-series Hurricane Ophelia (or at least the remnants of it) would be heading for these shores; I hope this is coincidence and not karma for me criticising the US National Weather Service’s diagrams!
As we batten down here, an odd occurrence was brought to my attention by Bill McKibben (@billmckibben), someone I connected with while working on this set of articles. Here is what he tweeted:
I am sure that inhabitants of both the Shetland Islands and the East Midlands will be breathing sighs of relief!
Clearly both the northward and eastward extent of Ophelia was outside of the scope of either the underlying model or the mapping software. A useful reminder to data professionals to ensure we set the boundaries of both modelling and visualisation work appropriately.
As an aside, this image is another for the Hall of Infamy, relying as it does on the less than helpful rainbow palette we critiqued all the way back in the first article.
I’ll hope to be writing again soon – hurricanes allowing!
In the first article in this mini-series we looked at alternative approaches to colour and how these could inform or mislead in data visualisations relating to weather events. In particular we discussed drawbacks of using a rainbow palette in such visualisations and some alternatives. Here we move into much more serious territory, how best to inform the public about what a specific hurricane will do next and the risks that it poses. It would not be an exaggeration to say that sometimes this area may be a matter of life and death. As with rainbow-coloured maps of weather events, some aspects of how the estimated future course of hurricanes are communicated and understood leave much to be desired.
The above diagram is called a the cone of uncertainty of a hurricane. Cone of uncertainty sounds like an odd term. What does it mean? Let’s start by offering a historical perspective on hurricane modelling.
Paleomodelling
Well like any other type of weather prediction, determining the future direction and speed of a hurricane is not an exact science [2]. In the earlier days of hurricane modelling, Meteorologists used to employ statistical models, which were built based on detailed information about previous hurricanes, took as input many data points about the history of a current hurricane’s evolution and provided as output a prediction of what it could do in coming days.
There were a variety of statistical models, but the output of them was split into two types when used for hurricane prediction.
A) A prediction of the next location of the hurricane was made. This included an average error (in km) based on the inaccuracy of previous hurricane predictions. A percentage of this, say 80%, gave a “circle of uncertainty”, x km around the prediction.
B) Many predictions were generated and plotted; each had a location and an probability associated with it. The centroid of these (adjusted by the probability associated with each location) was calculated and used as the central prediction (cf. A). A circle was drawn (y km from the centroid) so that a percentage of the predictions fell within this. Above, there are 100 estimates and the chosen percentage is 80%; so 80 points lie within the red “circle of uncertainty”.
Type A
First, the model could have generated a single prediction (the centre of the hurricane will be at 32.3078° N, 64.7505° W tomorrow) and supplemented this with an error measure. The error measure would have been based on historical hurricane data and related to how far out prior predictions had been on average; this measure would have been in kilometres. It would have been typical to employ some fraction of the error measure to define a “circle of uncertainty” around the central prediction; 80% in the example directly above (compared to two thirds in the NWS exhibit at the start of the article).
Type B
Second, the model could have generated a large number of mini-predictions, each of which would have had a probability associated with it (e.g. the first two estimates of location could be that the centre of the hurricane is at 32.3078° N, 64.7505° W with a 5% chance, or a mile away at 32.3223° N, 64.7505° W with a 2% chance and so on). In general if you had picked the “centre of gravity” of the second type of output, it would have been analogous to the single prediction of the first type of output [3]. The spread of point predictions in the second method would have also been analogous to the error measure of the first. Drawing a circle around the centroid would have captured a percentage of the mini-predictions, once more 80% in the example immediately above and two thirds in the NWS chart, generating another “circle of uncertainty”.
Here comes the Science
That was then of course, nowadays the statistical element of hurricane models is less significant. With increased processing power and the ability to store and manipulate vast amounts of data, most hurricane models instead rely upon scientific models; let’s call this Type C.
Type C
As the air is a fluid [4], its behaviour falls into the area of study known as fluid dynamics. If we treat the atmosphere as being viscous, then the appropriate equation governing fluid dynamics is the Navier-Stokes equation, which is itself derived from the Cauchy Momentum equation:
If viscosity is taken as zero (as a simplification), instead the Euler equations apply:
The reader may be glad to know that I don’t propose to talk about any of the above equations any further.
To get back to the model, in general the atmosphere will be split into a three dimensional grid (the atmosphere has height as well). The current temperature, pressure, moisture content etc. are fed in (or sometimes interpolated) at each point and equations such as the ones above are used to determine the evolution of fluid flow at a given grid element. Of course – as is typical in such situations – approximations of the equations are used and there is some flexibility over which approximations to employ. Also, there may be uncertainty about the input parameters, so statistics does not disappear entirely. Leaving this to one side, how the atmospheric conditions change over time at each grid point rolls up to provide a predictive basis for what a hurricane will do next.
Although the methods are very different, the output of these scientific models will be pretty similar, qualitatively, to the Type A statistical model above. In particular, uncertainty will be delineated based on how well the model performed on previous occasions. For example, what was the average difference between prediction and fact after 6 hours, 12 hours and so on. Again, the uncertainty will have similar characteristics to that of Type A above.
A Section about Conics
In all of the cases discussed above, we have a central prediction (which may be an average of several predictions as per Type B) and a circular distribution around this indicating uncertainty. Let’s consider how these predictions might change as we move into the future.
If today is Monday, then there will be some uncertainty about what the hurricane does on Tuesday. For Wednesday, the uncertainty will be greater than for Tuesday (the “circle of uncertainty” will have grown) and so on. With the Type A and Type C outputs, the error measure will increase with time. With the Type B output, if the model spits out 100 possible locations for the hurricane on a specific day (complete with the likelihood of each of these occurring), then these will be fairly close together on Tuesday and further apart on Wednesday. In all cases, uncertainty about the location of the becomes smeared out over time, resulting in a larger area where it is likely to be located and a bigger “circle of uncertainty”.
This is where the circles of uncertainty combine to become a cone of uncertainty. For the same example, on each day, the meteorologists will plot the central prediction for the hurricane’s location and then draw a circle centered on this which captures the uncertainty of the prediction. For the same reason as stated above, the size of the circle will (in general) increase with time; Wednesday’s circle will be bigger than Tuesday’s. Also each day’s central prediction will be in a different place from the previous day’s as the hurricane moves along. Joining up all of these circles gives us the cone of uncertainty [5].
If the central predictions imply that a hurricane is moving with constant speed and direction, then its cone of uncertainty would look something like this:
In this diagram, broadly speaking, on each day, there is a 67% probability that the centre of the hurricane will be found within the relevant circle that makes up the cone of uncertainty. We will explore the implications of the underlined phrase in the next section.
Of course hurricanes don’t move in a single direction at an unvarying pace (see the actual NWS exhibit above as opposed to my idealised rendition), so part of the purpose of the cone of uncertainty diagram is to elucidate this.
The Central Issue
So hopefully the intent of the NWS chart at the beginning of this article is now clearer. What is the problem with it? Well I’ll go back to the words I highlighted couple of paragraphs back:
There is a 67% probability that the centre of the hurricane will be found within the relevant circle that makes up the cone of uncertainty
So the cone helps us with where the centre of the hurricane may be. A reasonable question is, what about the rest of the hurricane?
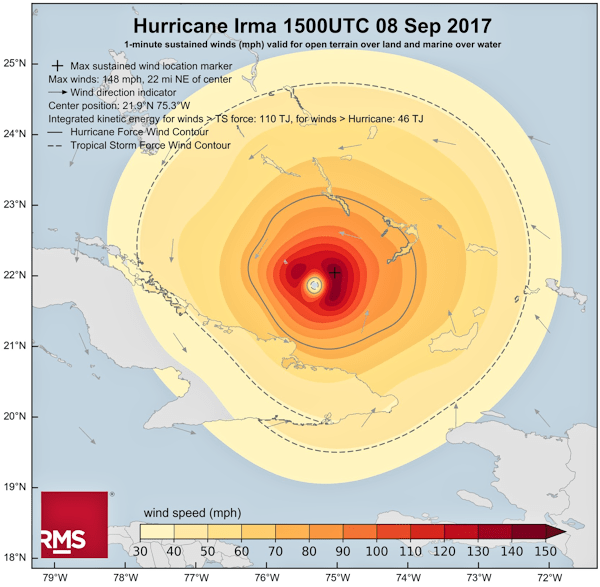
For ease of reference, here is the NWS exhibit again:
Let’s first of all pause to work out how big some of the NWS “circles of uncertainty” are. To do this we can note that the grid lines (though not labelled) are clearly at 5° intervals. The distance between two lines of latitude (ones drawn parallel to the equator) that are 1° apart from each other is a relatively consistent number; approximately 111 km [6]. This means that the lines of latitude on the page are around 555 km apart. Using this as a reference, the “circle of uncertainty” labelled “8 PM Sat” has a diameter of about 420 km (260 miles).
Let’s now consider how big Hurricane Irma was [7].
Aside: I’d be remiss if I didn’t point out here that RMS have selected what seems to me to be a pretty good colour palette in the chart above.
Well there is no defined sharp edge of a hurricane, rather the speed of winds tails off as may be seen in the above diagram. In order to get some sense of the size of Irma, I’ll use the dashed line in the chart that indicates where wind speeds drop below that classified as a tropical storm (65 kmph or 40 mph [8]). This area is not uniform, but measures around 580 km (360 miles) wide.
A) The size of the hurricane is greater than the size of the “circle of uncertainty”, the former extends 80 km beyond the circumference of the latter in all directions.
B) The “circle of uncertainty” captures the area within which the hurricane’s centre is likely to fall. But this includes cases where the centre of the hurricane is on the circumference of the “circle of uncertainty”. This means the the furthermost edge of the hurricane could be up to 290 km outside of the “circle of uncertainty”.
There are two issues here, which are illustrated in the above diagram.
Issue A
Irma was actually bigger [9] than at least some of the “circles of uncertainty”. A cursory glance at the NWS exhibit would probably give the sense that the cone of uncertainty represents the extent of the storm, it doesn’t. In our example, Irma extends 80 km beyond the “circle of uncertainty” we measured above. If you thought you were safe because you were 50 km from the edge of the cone, then this was probably an erroneous conclusion.
Issue B
Even more pernicious, because each “circle of uncertainty” provides an area within which the centre of the hurricane could be situated, this includes cases where the centre of the hurricane sits on the circumference of the “circle of uncertainty”. This, together with the size of the storm, means that someone 290 km from the edge of the “circle of uncertainty” could suffer 65 kmph (40 mph) winds. Again, based on the diagram, if you felt that you were guaranteed to be OK if you were 250 km away from the edge of the cone, you could get a nasty surprise.
These are not academic distinctions, the real danger that hurricane cones were misinterpreted led the NWS to start labelling their charts with “This cone DOES NOT REPRESENT THE SIZE OF THE STORM!!” [10].
Even Florida senator Marco Rubio got in on the act, tweeting:
When you need a politician help you avoid misinterpreting a data visualisation, you know that there is something amiss.
In Summary
The last thing I want to do is to appear critical of the men and women of the US National Weather Service. I’m sure that they do a fine job. If anything, the issues we have been dissecting here demonstrate that even highly expert people with a strong motivation to communicate clearly can still find it tough to select the right visual metaphor for a data visualisation; particularly when there is a diverse audience consuming the results. It also doesn’t help that there are many degrees of uncertainty here: where might the centre of the storm be? how big might the storm be? how powerful might the storm be? in which direction might the storm move? Layering all of these onto a single exhibit while still rendering it both legible and of some utility to the general public is not a trivial exercise.
The cone of uncertainty is a precise chart, so long as the reader understands what it is showing and what it is not. Perhaps the issue lies more in the eye of the beholder. However, having to annotate your charts to explain what they are not is never a good look on anyone. The NWS are clearly aware of the issues, I look forward to viewing whatever creative solution they come up with later this hurricane season.
Acknowledgements
I would like to thank Dr Steve Smith, Head of Catastrophic Risk at Fractal Industries, for reviewing this piece and putting me right on some elements of modern hurricane prediction. I would also like to thank my friend and former colleague, Dr Raveem Ismail, also of Fractal Industries, for introducing me to Steve. Despite the input of these two experts, responsibility for any errors or omissions remains mine alone.
I don’t mean to imply by this that the estimation process is unscientific of course. Indeed, as we will see later, hurricane prediction is becoming more scientific all the time.
[3]
If both methods were employed in parallel, it would not be too surprising if their central predictions were close to each other.
[4]
A gas or a liquid.
[5]
A shape traced out by a particle traveling with constant speed and with a circle of increasing radius inscribed around it would be a cone.
[6]
The distance between lines of longitude varies between 111 km at the equator and 0 km at either pole. This is because lines of longitude are great circles (or meridians) that meet at the poles. Lines of latitude are parallel circles (parallels) progressing up and down the globe from the equator.
[7]
At a point in time of course. Hurricanes change in size over time as well as in their direction/speed of travel and energy.
[8]
I am rounding here. The actual threshold values are 63 kmph and 39 mph.
[9]
Using the definition of size that we have adopted above.
[10]
Their use of capitals, bold and multiple exclamation marks.
Today the recipients of the 2017 Nobel Prize for Chemistry were announced [1]. I was delighted to learn that one of the three new Laureates was Richard Henderson, former Director of the UK Medical Research Council’s Laboratory of Molecular Biology in Cambridge; an institute universally known as the LMB. Richard becomes the fifteenth Nobel Prize winner who worked at the LMB. The fourteenth was Venkatraman Ramakrishnan in 2009. Venki was joint Head of Structural Studies at the LMB, prior to becoming President of the Royal Society [2].
I have mentioned the LMB in these pages before [3]. In my earlier article, which focussed on Data Visualisation in science, I also provided a potted history of X-ray crystallography, which included the following paragraph:
Today, X-ray crystallography is one of many tools available to the structural biologist with other approaches including Nuclear Magnetic Resonance Spectroscopy, Electron Microscopy and a range of biophysical techniques.
I have highlighted the term Electron Microscopy above and it was for his immense contributions to the field of Cryo-electron Microscopy (Cryo-EM) that Richard was awarded his Nobel Prize; more on this shortly.
First of all some disclosure. The LMB is also my wife’s alma mater, she received her PhD for work she did there between 2010 and 2014. Richard was one of two people who examined her as she defended her thesis [4]. As Venki initially interviewed her for the role, the bookends of my wife’s time at the LMB were formed by two Nobel laureates; an notable symmetry.
The press release about Richard’s Nobel Prize includes the following text:
The Nobel Prize in Chemistry 2017 is awarded to Jacques Dubochet, Joachim Frank and Richard Henderson for the development of cryo-electron microscopy, which both simplifies and improves the imaging of biomolecules. This method has moved biochemistry into a new era.
[…]
Electron microscopes were long believed to only be suitable for imaging dead matter, because the powerful electron beam destroys biological material. But in 1990, Richard Henderson succeeded in using an electron microscope to generate a three-dimensional image of a protein at atomic resolution. This breakthrough proved the technology’s potential.
Electron microscopes [5] work by passing a beam of electrons through a thin film of the substance being studied. The electrons interact with the constituents of the sample and go on to form an image which captures information about these interactions (nowadays mostly on an electronic detector of some sort). Because the wavelength of electrons [6] is so much shorter than light [7], much finer detail can be obtained using electron microscopy than with light microscopy. Indeed electron microscopes can be used to “see” structures at the atomic scale. Of course it is not quite as simple as printing out the image snapped by you SmartPhone. The data obtained from electron microscopy needs to be interpreted by software; again we will come back to this point later.
Cryo-EM refers to how the sample being examined is treated prior to (and during) microscopy. Here a water-suspended sample of the substance is frozen (to put it mildly) in liquid ethane to temperatures around -183 °C and maintained at that temperature during the scanning procedure. The idea here is to protect the sample from the damaging effects of the cathode rays [8] it is subjected to during microscopy.
A Matter of Interpretation
On occasion, I write articles which are entirely scientific or mathematical in nature, but more frequently I bring observations from these fields back into my own domain, that of data, information and insight. This piece will follow the more typical course. To do this, I will rely upon a perspective that Richard Henderson wrote for the Proceedings of the National Academy of Science back in 2013 [9].
Here we come back to the interpretation of Cryo-EM data in order to form an image. In the article, Richard refers to:
[Some researchers] who simply record images, follow an established (or sometimes a novel or inventive [10]) protocol for 3D map calculation, and then boldly interpret and publish their map without any further checks or attempts to validate the result. Ten years ago, when the field was in its infancy, referees would simply have to accept the research results reported in manuscripts at face value. The researchers had recorded images, carried out iterative computer processing, and obtained a map that converged, but had no way of knowing whether it had converged to the true structure or some complete artifact. There were no validation tests, only an instinct about whether a particular map described in the publication looked right or wrong.
The title of Richard’s piece includes the phrase “Einstein from noise”. This refers to an article published in the Journal of Structural Biology in 2009 [11]. Here the authors provided pure white noise (i.e. a random set of black and white points) as the input to an Algorithm which is intended to produce EM maps and – after thousands of iterations – ended up with the following iconic mage:
Richard lists occurrences of meaning being erroneously drawn from EM data from his own experience of reviewing draft journal articles and cautions scientists to hold themselves to the highest standards in this area, laying out meticulous guidelines for how the creation of EM images should be approached, checked and rechecked.
The obvious correlation here is to areas of Data Science such as Machine Learning. Here again algorithms are applied iteratively to data sets with the objective of discerning meaning. Here too conscious or unconscious bias on behalf of the people involved can lead to the business equivalent of Einstein ex machina. It is instructive to see the level of rigour which a Nobel Laureate views as appropriate in an area such as the algorithmic processing of data. Constantly questioning your results and validating that what emerges makes sense and is defensible is just one part of what can lead to gaining a Nobel Prize [12]. The opposite approach will invariably lead to disappointment in either academia or in business.
Having introduced a strong cautionary note, I’d like to end this article with a much more positive tone by extending my warm congratulations to Richard both for his well-deserved achievement, but more importantly for his unwavering commitment to rolling back the bounds of human knowledge.
If you are interested in learning more about Cryo-Electron Microscopy, the following LMB video, which features Richard Henderson and colleagues, may be of interest:
Her thesis was passed without correction – an uncommon occurrence – and her contribution to the field was described as significant in the formal documentation.
[5]
More precisely this description applies to Transmission Electron Microscopes, which are the type of kit used in Cryo-EM.
[6]
The wave-particle duality that readers may be familiar with when speaking about light waves / photons also applies to all sub-atomic particles. Electrons have both a wave and a particle nature and so, in particular, have wavelengths.
[7]
This is still the case even if ultraviolet or more energetic light is used instead of visible light.
[8]
Cathode rays are of course just beams of electrons.
Since its launch in August of this year, the peterjamesthomas.com Data and Analytics Dictionary has received a welcome amount of attention with various people on different social media platforms praising its usefulness, particularly as an introduction to the area. A number of people have made helpful suggestions for new entries or improvements to existing ones. I have also been rounding out the content with some more terms relating to each of Data Governance, Big Data and Data Warehousing. As a result, The Dictionary now has over 80 main entries (not including ones that simply refer the reader to another entry, such as Linear Regression, which redirects to Model).
Regular readers may recall my March 2017 article [1] which started by exploring failure rates of Big Data implementations. In this, amongst other facts, we learnt that between a half and two-thirds of a range of major business transformations fail to deliver lasting value [2]. After recently reading a pair of Harvard Business Review articles from back in 2016 [3], I can also add Analytics. Here is a salient quote from the second article:
Only a little more than one in three of the three-dozen companies that we studied met the objectives of their analytics initiatives over the long term. Clearly, driving major innovations with analytics was harder than many executives expected.
Once more we see what appears to be a fundamental constant emerge, around 60% of most major business endeavours cannot be classified as unqualified successes. I feel that we should come up with a name for this figure and ideally use a Greek letter to denote it, maybe φ which is as close to “F” for failure as the Greek alphabet gets [4].
The authors based their study on a 20 years of research spanning 36 client companies. The drew a surprising conclusion:
Efforts to adopt analytics upset the balance of power in the C-suite, and this shift often had a negative impact on analytics initiatives.
As ever (and as indeed I concluded in my previous article) reasons for failure have little to do with technology and everything to do with humans and how they interact with each other. This is one of the reasons I get incensed by Analytics teams saying things like “the business didn’t know what they wanted” or “adoption wasn’t strong enough” when their programmes fail.
For a start, Analytics is a business discipline and the Analytics team should view themselves as a business team. Second, to me it is pretty clear that a core activity for such teams is working with stakeholders to form an appreciation of their products or services, their competitive landscape, the markets they operate in, their day-to-day challenges and, on top of all this, what they want from data; even if this requires some teasing out (e.g. spending time shadowing people or using mock-ups or prototypes to show the art of the possible). Also Analytics teams must take accountability for driving adoption themselves, rather than assuming that someone else will deal with this, or worse, that “if we build it, they will come” [5].
The C-suite aspect is tougher, but in my own work I try to spend time with Executives to understand their world views and to make sure I align what I am doing with their priorities. Building relationships here can help to reduce the likelihood of Executive strife impacting on an Analytics programme. However, I do also agree with the authors that the CEO has a key role to play here in ensuring that his or her team embrace becoming a data-driven organisation, even if this means changes in roles and responsibilities for some.
I’d encourage readers to take a look at the original HBR material, it contains a number of other pertinent observations above and beyond the ones I have highlighted here. When either looking to prevent issues from arising, or trying to mitigating them once they do, my article, 20 Risks that Beset Data Programmes, can also be a useful reference.
Beyond this, my simplest advice is to always remember the human angle in any Analytics programme. This is more likely to determine success or failure than technical excellence, or embracing the latest and greatest Data Visualisation or Analysis tools [6].
This also includes a quote from Samuel Beckett, which provided the inspiration for the title of this article.
[2]
The specifics were, Big Data implementations, Data Warehousing, ERP systems and Mergers and Acquisitions; please see the earlier article for the source of the figures.
To this you could add any number of technology-based programmes, such as CRM implementations, Digital Transformation and even outsourcing. The main message is doing some things successfully is hard.
La Gioconda – by Leonardo da Vinci
(painted some time between 1503 and 1506)
The first half of my planned thoughts on Hurricanes and Data Visualisation is called Rainbow’s Gravity and was published earlier this week. Part two, Map Reading, has now also been published. Here is an unplanned post slotting into the gap between the two.
The image above is iconic enough to require no introduction. In response to my article about the use of a rainbow palette Quora user Hyunjun Ji decided to illustrate the point using this famous painting. Here is the Mona Lisa rendered using a rainbow colour map:
Here is the same image using the viridis colormap [1]:
The difference in detail conveyed between these two images is vast. I’ll let Hyunjun explain in his own words [2]:
In these images, the rainbow color map might look colorful, but for example, if you take a look at the neck and forehead, you observe a very rapid red to green color change.
Another thing about the rainbow colormap is that it is not uniform, especially in terms of brightness. When you go from small to large data, its brightness does not monotonically increase or decrease. Instead, it goes up and down, confusing human perception.
To emphasise his point, Hyunjun then converted the rainbow Mona Lisa back to greyscale, this final image really brings home how much information is lost by adopting a rainbow palette.
Hyunjun’s points were striking enough for me to want to share them with a wider audience and I thank him for providing this pithy insight.
According to its creators, viridis is designed to be:
Colorful, spanning as wide a palette as possible so as to make differences easy to see,
Perceptually uniform, meaning that values close to each other have similar-appearing colors and values far away from each other have more different-appearing colors, consistently across the range of values,
Robust to colorblindness, so that the above properties hold true for people with common forms of colorblindness, as well as in grey scale printing, and
This is the first of two articles whose genesis was the nexus of hurricanes and data visualisation. The second article, Part II – Map Reading, has now been published.
Introduction
This first article is not a critique of Thomas Pynchon‘s celebrated work, instead it refers to a grave malady that can afflict otherwise health data visualisations; the use and abuse of rainbow colours. This is an area that some data visualisation professionals can get somewhat hot under the collar about; there is even a Twitter hashtag devoted to opposing this colour choice, #endtherainbow.
The [mal-] practice has come under additional scrutiny in recent weeks due to the major meteorological events causing so much damage and even loss of life in the Caribbean and southern US; hurricanes Harvey and Irma. Of course the most salient point about these two megastorms is their destructive capability. However the observations that data visualisers make about how information about hurricanes is conveyed do carry some weight in two areas; how the public perceives these phenomena and how they perceive scientific findings in general [1]. The issues at stake are ones of both clarity and inclusiveness. Some of these people felt that salt was rubbed in the wound when the US National Weather Service, avid users of rainbows [2], had to add another colour to their normal palette for Harvey:
In 2015, five scientists collectively wrote a letter to Nature entitled “Scrap rainbow colour scales” [3]. In this they state:
It is time to clamp down on the use of misleading rainbow colour scales that are increasingly pervading the literature and the media. Accurate graphics are key to clear communication of scientific results to other researchers and the public — an issue that is becoming ever more important.
At this point I have to admit to using rainbow colour schemes myself professionally and personally [4]; it is often the path of least resistance. I do however think that the #endtherainbow advocates have a point, one that I will try to illustrate below.
Many Marvellous Maps
Let’s start by introducing the idyllic coastal county of Thomasshire, a map of which appears below:
Of course this is a cartoon map, it might be more typical to start with an actual map from Google Maps or some other provider [5], but this doesn’t matter to the argument we will construct here. Let’s suppose that – rather than anything as potentially catastrophic as a hurricane – the challenge is simply to record the rainfall due to a nasty storm that passed through this shire [6]. Based on readings from various weather stations (augmented perhaps by information drawn from radar), rainfall data would be captured and used to build up a rain contour map, much like the elevation contour maps that many people will recall from Geography lessons at school [7].
If we were to adopt a rainbow colour scheme, then such a map might look something like the one shown below:
Here all areas coloured purple will have received between 0 and 10 cm of rain, blue between 10 and 20 cm of rain and so on.
At this point I apologise to any readers who suffer from migraine. An obvious drawback of this approach is how garish it is. Also the solid colours block out details of the underlying map. Well something can be done about both of these issues by making the contour colours transparent. This both tones them down and allows map details to remain at least semi-visible. This gets us a new map:
Here we get into the core of the argument about the suitability of a rainbow palette. Again quoting from the Nature letter:
[…] spectral-type colour palettes can introduce false perceptual thresholds in the data (or hide genuine ones); they may also mask fine detail in the data. These palettes have no unique perceptual ordering, so they can de-emphasize data extremes by placing the most prominent colour near the middle of the scale.
[…]
Journals should not tolerate poor visual communication, particularly because better alternatives to rainbow scales are readily available (see NASA Earth Observatory).
In our map, what we are looking to do is to show increasing severity of the deluge as we pass from purple (indigo / violet) up to red. But the ROYGBIV [8] colours of the spectrum are ill-suited to this. Our eyes react differently to different colours and will not immediately infer the gradient in rainfall that the image is aiming to convey. The NASA article the authors cite above uses a picture to paint a thousand words:
Compared to a monochromatic or grayscale palette the rainbow palette tends to accentuate contrast in the bright cyan and yellow regions, but blends together through a wide range of greens. Sourced from NASA
Another salient point is that a relatively high proportion of people suffer from one or other of the various forms of colour blindness [9]. Even the most tastefully pastel rainbow chart will disadvantage such people seeking to derive meaning from it.
Getting Over the Rainbow
So what could be another approach? Well one idea is to show gradients of whatever the diagram is tracking using gradients of colour; this is the essence of the NASA recommendation. I have attempted to do just this in the next map.
I chose a bluey-green tone both as it was to hand in the Visio palette I was using and also to avoid confusion with the blue sea (more on this later). Rather than different colours, the idea is to map intensity of rainfall to intensity of colour. This should address both colour-blindness issues and the problems mentioned above with discriminating between ROYGBIV colours. I hope that readers will agree that it is easier to grasp what is happening at a glance when looking at this chart than in the ones that preceded it.
However, from a design point of view, there is still one issue here; the sea. There are too many bluey colours here for my taste, so let’s remove the sea colouration to get:
Some purists might suggest also turning the land white (or maybe a shade of grey), others would mention that the grid-lines add little value (especially as they are not numbered). Both would probably have a point, however I think that use can also push minimalism too far. I am pretty happy that our final map delivers the information it is intended to convey much more accurately and more immediately than any of its predecessors.
Comparing the first two rainbow maps to this last one, it is perhaps easy to see why so many people engaged in the design of data visualisations want to see an end to ROYGBIV palettes. In the saying, there is a pot of gold at the end of the rainbow, but of course this can never be reached. I strongly suspect that, despite the efforts of the #endtherainbow crowd, an end to the usage of this particular palette will be equally out of reach. However I hope that this article is something that readers will bear in mind when next deciding on how best to colour their business graph, diagram or data visualisation. I am certainly going to try to modify my approach as well.
The story of hurricanes and data visualisation will continue in Part II – Map Reading, which is currently forthcoming.
Notes
[1]
For some more thoughts on the public perception of science, see Toast.
[2]
I guess it’s appropriate from at least one point of view.
Ed Hawkins – National Centre for Atmospheric Science, University of Reading, UK (@ed_hawkins)
Doug McNeall – Met Office Hadley Centre, Exeter, UK (@dougmcneall)
Jonny Williams – University of Bristol, UK (LinkedIn page)
David B. Stephenson – University of Exeter, UK (Academic page)
David Carlson – World Meteorological Organization, Geneva, Switzerland (retired June 2017).
[4]
I did also go through a brief monochromatic phase, but it didn’t last long.
[5]
I guess it might take some time to find Thomasshire on Google Maps.
[6]
Based on the data I am graphing here, it was a very nasty storm indeed! In this article, I am not looking for realism, just to make some points about the design of diagrams.
Whereas contours on a physical geography map (see above) link areas with the same elevation above sea level, rainfall contour lines would link areas with the same precipitation.
[8]
Red, Orange, Yellow, Green, Blue, Indigo, Violet.
[9]
Red–green color blindness, the most common sort, affects 80 in 1,000 of males and 4 in 1,000 of females of Northern European descent.
“It is a truth universally acknowledged, that an organisation in possession of some data, must be in want of a Chief Data Officer”
— Growth and Governance, by Jane Austen (1813) [1]
I wrote about a theoretical job description for a Chief Data Officer back in November 2015 [2]. While I have been on “paternity leave” following the birth of our second daughter, a couple of genuine CDO job specs landed in my inbox. While unable to respond for the aforementioned reasons, I did leaf through the documents. Something immediately struck me; they were essentially wish-lists covering a number of data-related fields, rather than a description of what a CDO might actually do. Clearly I’m not going to cite the actual text here, but the following is representative of what appeared in both requirement lists:
Mandatory Requirements:
Solid commercial understanding and 5 years spent in [insert industry sector here]
The above list may have descended into farce towards the end, but I would argue that the problems started to occur much earlier. The above is not a description of what is required to be a successful CDO, it’s a description of a Swiss Army Knife. There is also the minor practical point that, out of a World population of around 7.5 billion, there may well be no one who ticks all the boxes [4].
Let’s make the fallacy of this type of job description clearer by considering what a simmilar approach would look like if applied to what is generally the most senior role in an organisation, the CEO. Whoever drafted the above list of requirements would probably characterise a CEO as follows:
The best salesperson in the organisation
The best accountant in the organisation
The best M&A person in the organisation
The best customer service operative in the organisation
The best facilities manager in the organisation
The best janitor in the organisation
The best purchasing clerk in the organisation
The best lawyer in the organisation
The best programmer in the organisation
The best marketer in the organisation
The best product developer in the organisation
The best HR person in the organisation, etc., etc., …
Of course a CEO needs to be none of the above, they need to be a superlative leader who is expert at running an organisation (even then, they may focus on plotting the way forward and leave the day to day running to others). For the avoidance of doubt, I am not saying that a CEO requires no domain knowledge and has no expertise, they would need both, however they don’t have to know every aspect of company operations better than the people who do it.
The same argument applies to CDOs. Domain knowledge probably should span most of what is in the job description (save for maybe the three items with footnotes), but knowledge is different to expertise. As CDOs don’t grow on trees, they will most likely be experts in one or a few of the areas cited, but not all of them. Successful CDOs will know enough to be able to talk to people in the areas where they are not experts. They will have to be competent at hiring experts in every area of a CDO’s purview. But they do not have to be able to do the job of every data-centric staff member better than the person could do themselves. Even if you could identify such a CDO, they would probably lose their best staff very quickly due to micromanagement.
A CDO has to be a conductor of both the data function orchestra and of the use of data in the wider organisation. This is a talent in itself. An internationally renowned conductor may have previously been a violinist, but it is unlikely they were also a flautist and a percussionist. They do however need to be able to tell whether or not the second trumpeter is any good or not; this is not the same as being able to play the trumpet yourself of course. The conductor’s key skill is in managing the efforts of a large group of people to create a cohesive – and harmonious – whole.
The CDO is of course still a relatively new role in mainstream organisations [5]. Perhaps these job descriptions will become more realistic as the role becomes more familiar. It is to be hoped so, else many a search for a new CDO will end in disappointment.
Having twisted her text to my own purposes at the beginning of this article, I will leave the last words to Jane Austen:
“A scheme of which every part promises delight, can never be successful; and general disappointment is only warded off by the defence of some little peculiar vexation.”
— Pride and Prejudice, by Jane Austen (1813)
Notes
[1]
Well if a production company can get away with Pride and Prejudice and Zombies, then I feel I am on reasonably solid ground here with this title.
I also seem to be riffing on JA rather a lot at present, I used Rationality and Reality as the title of one of the chapters in my [as yet unfinished] Mathematical book, Glimpses of Symmetry.
Most readers will immediately spot the obvious mistake here. Of course all three of these requirements should be mandatory.
[4]
To take just one example, gaining a PhD in a numerical science, a track record of highly-cited papers and also obtaining an MBA would take most people at least a few weeks of effort. Is it likely that such a person would next focus on a PRINCE2 or TOGAF qualification?
My objective in this brief article is to compare how much time and effort is spent on certain information-related activities in an organisation that has adopted best practice, compared to what is typical in all too many organisations. For the avoidance of doubt, when I say people here I am focussing on staff who would ostensibly be the consumers of information, not data professionals who are engaged in providing such information. What follows relates to the end users of information.
What I have done at the top of the above exhibit (labelled “Activity” on the left-hand side) is to lay out the different types of information-related work that end users engage in, splitting these into low, medium and high valued-added components as we scan across the page.
Low value is number crunching and prettifying exhibits for publication
Medium value is analysis and interpretation of information
High value is taking action based on insights and then monitoring to check whether the desired outcome has been achieved
In the centre of the diagram (labelled “Ideal Time Allocation”), I have shown what I believe is a best practice allocation of time to these activities. It is worth pointing out that that I am recommending that significant time (60%) is spent on analysis and interpretation; while tagged as of medium-value, this type of work is a prerequisite for the higher value activities, you cannot really avoid it. Despite this, there is a still 30% of time devoted to the high-value activities of action and monitoring of results. The remaining 10% is expended on low-value activities.
At the bottom of the chart (labelled “Actual Time Allocation”), I have tried to estimate how people’s time is actually spent in organisations where insufficient attention has been paid to the information landscape; a large number of organisations fit into this category in my experience. I am not trying to be 100% precise here, but I believe that the figures are representative of what I have seen in several organisations. In fact I think that the estimated amount of time spent on low value activities is probably greater than 70% in many cases; however I don’t want to be accused of exaggeration.
Clearly a lack of robust, reliable and readily available information can mean that highly skilled staff spend their time generating information rather than analysing and interpreting it and then using such insights as the basis for action. This results in the bulk of their work being low valued-added. The medium and high value activities are squeezed out as there are only so many hours in the day.
It is obvious that such a state of affairs is sub-optimal and needs to be addressed. My experience of using diagrams like the one shown here is that they can be very valuable in explaining what is wrong with current information arrangements and highlighting the need for change.
An interesting exercise is to estimate what the bottom of the diagram would look like for your organisation. Are you close to best practice, or some way from this and in need of urgent change?
I find myself frequently being asked questions around terminology in Data and Analytics and so thought that I would try to define some of the more commonly used phrases and words. My first attempt to do this can be viewed in a new page added to this site (this also appears in the site menu):
I plan to keep this up-to-date as the field continues to evolve.
I hope that my efforts to explain some concepts in my main area of specialism are both of interest and utility to readers. Any suggestions for new entries or comments on existing ones are more than welcome.








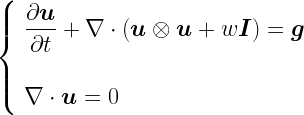






























")





