Larger, annotated PDF version (opens in a new tab)
Introduction
It is hard to find an organisation that does not aspire to being data-driven these days. While there is undoubtedly an element of me-tooism about some of these statements (or a fear of competitors / new entrants who may use their data better, gaining a competitive advantage), often there is a clear case for the better leverage of data assets. This may be to do with the stand-alone benefits of such an approach (enhanced understanding of customers, competitors, products / services etc. [1]), or as a keystone supporting a broader digital transformation.
However, in my experience, many organisations have much less mature ideas about how to achieve their data goals than they do about setting them. Given the lack of executive experience in data matters [2], it is not atypical that one of the large strategy consultants is engaged to shape a data strategy; one of the large management consultants is engaged to turn this into something executable and maybe to select some suitable technologies; and one of the large systems integrators (or increasingly off-shore organisations migrating up the food chain) is engaged to do the work, which by this stage normally relates to building technology capabilities, implementing a new architecture or some other technology-focussed programme.

Even if each of these partners does a great job – which one would hope they do at their price points – a few things invariably get lost along the way. These include:
- A data strategy that is closely coupled to the organisation’s actual needs rather than something more general.
While there are undoubtedly benefits in adopting best practice for an industry, there is also something to be said for a more tailored approach, tied to business imperatives and which may have the possibility to define the new best practice. In some areas of business, it makes sense to take the tried and tested approach, to be a part of the herd. In others – and data is in my opinion one of these – taking a more innovative and distinctive path is more likely to lead to success.
- Connective tissue between strategy and execution.
The distinctions between the three types of organisations I cite above are becoming more blurry (not least as each seeks to develop new revenue streams). This can lead to the strategy consultants developing plans, which get ripped up by the management consultants; the management consultants revisiting the initial strategy; the systems integrators / off-shorers replanning, or opening up technical and architecture discussions again. Of course this means the client paying at least twice for this type of work. What also disappears is the type of accountability that comes when the same people are responsible for developing a strategy, turning this into a practical plan and then executing this [3].
- Focus on the cultural aspects of becoming more data-driven.
This is both one of the most important factors that determines success or failure [4] and something that – frankly because it is not easy to do – often falls by the wayside. By the time that the third external firm has been on-boarded, the name of the game is generally building something (e.g. a Data Lake, or an analytics platform) rather than the more human questions of who will use this, in what way, to achieve which business objectives.
Of course a way to address the above is to allocate some experienced people (internal or external, ideally probably a blend) who stay the course from development of data strategy through fleshing this out to execution and who – importantly – can also take a lead role in driving the necessary cultural change. It also makes sense to think about engaging organisations who are small enough to tailor their approach to your needs and who will not force a “cookie cutter” approach. I have written extensively about how – with the benefit of such people on board – to run such a data transformation programme [5]. Here I am going to focus on just one phase of such a programme and often the most important one; getting going and building momentum.
A Third Way
There are a couple of schools of thought here:
- Focus on laying solid data foundations and thus build data capabilities that are robust and will stand the test of time.
- Focus on delivering something ASAP in the data arena, which will build the case for further investment.
There are points in favour of both approaches and criticisms that can be made of each as well. For example, while the first approach will be necessary at some point (and indeed at a relatively early one) in order to sustain a transformation to a data-driven organisation, it obviously takes time and effort. Exclusive focus on this area can use up money, political capital and try the patience of sponsors. Few business initiatives will be funded for years if they do not begin to have at least some return relatively soon. This remains the case even if the benefits down the line are potentially great.
Equally, the second approach can seem very productive at first, but will generally end up trying to make a silk purse out of a sow’s ear [6]. Inevitably, without improvements to the underlying data landscape, limitations in the type of useful analytics that be carried out will be reached; sometimes sooner that might be thought. While I don’t generally refer to religious topics on this blog [7], the Parable of the Sower is apposite here. Focussing on delivering analytics without attending to the broader data landscape is indeed like the seed that fell on stony ground. The practice yields results that spring up, only to wilt when the sun gets hot, given that they have no real roots [8].
So what to do? Well, there is a Third Way. This involves blending both approaches. I tend to think of this in the following way:

First of all, this is a cartoon, it is not intended to indicate actual percentages, just to illustrate a general trend. In real life, it is likely that you will cycle round multiple times and indeed have different parallel work-streams at different stages. The general points I am trying to convey with this diagram are:
- At the beginning of a data transformation programme, there should probably be more emphasis on interim delivery and tactical changes. However, imoportantly, there is never zero strategic work. As things progress, the emphasis should swing more to strategic, long-term work. But again, even in a mature programme, there is never zero tactical work. There can also of course be several iterations of such shifts in approach.
- Interim and tactical steps should relate to not just analytics, but also to making point fixes to the data landscape where possible. It is also important to kick off diagnostic work, which will establish how bad things are and also suggest areas which could be attacked sooner rather than later; this too can initially be done on a tactical basis and then made more robust later. In general, if you consider the span of strategic data work, it makes sense to kick off cut-down (and maybe drastically cut-down) versions of many activities early on.
- Importantly, the tactical and strategic work-streams should not be hermetically sealed. What you actually want is healthy interplay. Building some early, “quick and dirty” analytics may highlight areas that should be covered by a data audit, or where there are obvious weaknesses in a data architecture. Any data assets that are built on a more strategic basis should also be leveraged by tactical work, improving its utility and probably increasing its lifespan.
Interconnected Activities
At the beginning of this article, I present a diagram (repeated below) which covers three types of initial data activities, the sort of work that – if executed competently – can begin to generate momentum for a data programme. The exhibit also references Data Strategy.
Larger, annotated PDF version (opens in a new tab)
Let’s look at each of these four things in some more detail:
- Analytic Point Solutions
Where data has historically been locked up in either hard-to-use repositories or in source systems themselves, liberating even a bit of it can be very helpful. This does not have to be with snazzy tools (unless you want to showcase the art of the possible). An anecdote might help to explain.
At one organisation, they had existing reporting that was actually not horrendous, but it was hard to access, hard to parameterise and hard to do follow-on analysis on. I took it upon myself to run 30 plus reports on a weekly and monthly basis, download the contents to Excel, front these with some basic graphs and make these all available on an intranet. This meant that people from Country A or Department B could go straight to their figures rather than having to run fiddly reports. It also meant that they had an immediate visual overview – including some comparisons to prior periods and trends over time (which were not available in the original reports). Importantly, they also got a basic pivot table, which they could use to further examine what was going on. These simple steps (if a bit laborious for me) had a massive impact. I later replaced the Excel with pages I wrote in a new web-reporting tool we built in house. Ultimately, my team moved these to our strategic Analytics platform.
This shows how point solutions can be very valuable and also morph into more strategic facilities over time.
- Data Process Improvements
Data issues may be to do with a range of problems from poor validation in systems, to bad data integration, but immature data processes and insufficient education for data entry staff are often key conributors to overall problems. Identifying such issues and quantifying their impact should be the province of a Data Audit, which is something I would recommend considering early on in a data programme. Once more this can be basic at first, considering just superficial issues, and then expand over time.
While fixing some data process problems and making a stepped change in data quality will both probably take time an effort, it may be possible to identify and target some narrower areas in which progress can be made quite quickly. It may be that one key attribute necessary for analysis is poorly entered and validated. Some good communications around this problem can help, better guidance for people entering it is also useful and some “quick and dirty” reporting highlighting problems and – hopefully – tracking improvement can make a difference quicker than you might expect [9].
- Data Architecture Enhancements
Improving a Data Architecture sounds like a multi-year task and indeed it can often be just that. However, it may be that there are some areas where judicious application of limited resource and funds can make a difference early on. A team engaged in a data programme should seek out such opportunities and expect to devote time and attention to them in parallel with other work. Architectural improvements would be best coordinated with data process improvements where feasible.
An example might be providing a web-based tool to look up valid codes for entry into a system. Of course it would be a lot better to embed this functionality in the system itself, but it may take many months to include this in a change schedule whereas the tool could be made available quickly. I have had some success with extending such a tool to allow users to build their own hierarchies, which can then be reflected in either point analytics solutions or more strategic offerings. It may be possible to later offer the tool’s functionality via web-services allowing it to be integrated into more than one system.
- Data Strategy
I have written extensively about Data Strategy on this site [10]. What I wanted to cover here is the interplay between Data Strategy and some of the other areas I have just covered. It might be thought that Data Strategy is both carved on tablets of stone [11] and stands in splendid and theoretical isolation, but this should not ever be the case. The development of a Data Strategy should of course be informed by a situational analysis and a vision of “what good looks like” for an organisation. However, both of these things can be shaped by early tactical work. Taking cues from initial tactical work should lead to a more pragmatic strategy, more aligned to business realities.
Work in each of the three areas itemised above can play an important role in shaping a Data Strategy and – as the Data Strategy matures – it can obviously guide interim work as well. This should be an iterative process with lots of feedback.
Closing Thoughts
I have captured the essence of these thoughts in the diagram above. The important things to take away are that in order to generate momentum, you need to start to do some stuff; to extend the physical metaphor, you have to start pushing. However, momentum is a vector quantity (it has a direction as well as a magnitude [12]) and building momentum is not a lot of use unless it is in the general direction in which you want to move; so push with some care and judgement. It is also useful to realise that – so long as your broad direction is OK – you can make refinements to your direction as you pick up speed.
The above thoughts are based on my experience in a range of organisations and I am confident that they can be applied anywhere, making allowance for local cultures of course. Once momentum is established, it still needs to be maintained (or indeed increased), but I find that getting the ball moving in the first place often presents the greatest challenge. My hope is that the framework I present here can help data practitioners to get over this initial hurdle and begin to really make a difference in their organisations.
Further reading on this subject:
- Vision vs Pragmatism
- Holistic vs Incremental approaches to BI
- Tactical Meandering
- Incremental Progress and Rock Climbing
Notes
| [1] |
Way back in 2009, I wrote about the benefits of leveraging data to provide enhanced information. The article in question was tited Measuring the benefits of Business Intelligence. Everything I mention remains valid today in 2018. |
| [2] |
See also: |
| [3] |
If I many be allowed to blow my own trumpet for a moment, I have developed data / information strategies for eight organisations, turned seven of these into a costed / planned programme and executed at least the first few phases of six of these. I have always found being a consistent presence through these phases has been beneficial to the organisations I was helping, as well as helping to reduce duplication of work. |
| [4] |
See my, now rather venerable, trilogy about cultural change in data / information programmes: together with the rather more recent: |
| [5] |
See for example: |
| [6] |
Dictionary.com offers a nice explanation of this phrase.. |
| [7] |
I was raised a Catholic, but have been areligious for many years. |
| [8] |
Much like 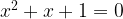 . .
For anyone interested, the two roots of this polynomial are clearly: neither of which is Real. |
| [9] |
See my rather venerable article, Using BI to drive improvements in data quality, for a fuller treatment of this area. |
| [10] |
For starters see:
and also the Data Strategy segment of The Anatomy of a Data Function – Part I. |
| [11] |
 |
| [12] |
See Glimpses of Symmetry, Chapter 15 – It’s Space Jim…. |

From: peterjamesthomas.com, home of The Data and Analytics Dictionary, The Anatomy of a Data Function and A Brief History of Databases