The Periodic Table, is one of the truly iconic scientific images [1], albeit one with a variety of forms. In the picture above, the normal Periodic Table has been repurposed in a novel manner to illuminate a different field of scientific enquiry. This version was created by Professor Jennifer Johnson (@jajohnson51) of The Ohio State University and the Sloan Digital Sky Survey (SDSS). It comes from an article on the SDSS blog entitled Origin of the Elements in the Solar System; I’d recommend reading the original post.
The historical perspective
A modern rendering of the Periodic Table appears above. It probably is superfluous to mention, but the Periodic Table is a visualisation of an underlying principle about elements; that they fall into families with similar properties and that – if appropriately arranged – patterns emerge with family members appearing at regular intervals. Thus the Alkali Metals [2], all of which share many important characteristics, form a column on the left-hand extremity of the above Table; the Noble Gases [3] form a column on the far right; and, in between, other families form further columns.
Given that the underlying principle driving the organisation of the Periodic Table is essentially a numeric one, we can readily see that it is not just a visualisation, but a data visualisation. This means that Professor Johnson and her colleagues are using an existing data visualisation to convey new information, a valuable technique to have in your arsenal.
One of the original forms of the Periodic Table appears above, alongside its inventor, Dmitri Mendeleev.
As with most things in science [4], my beguilingly straightforward formulation of “its inventor” is rather less clear-cut in practice. Mendeleev’s work – like Newton’s before him – rested “on the shoulders of giants” [5]. However, as with many areas of scientific endeavour, the chain of contributions winds its way back a long way and specifically to one of the greatest exponents of the scientific method [6], Antoine Lavoisier. The later Law of Triads [7], was another significant step along the path and – to mix a metaphor – many other scientists provided pieces of the jigsaw puzzle that Mendeleev finally assembled. Indeed around the same time as Mendeleev published his ideas [8], so did the much less celebrated Julius Meyer; Meyer and Mendeleev’s work shared several characteristics.
The epithet of inventor attached to Mendeleev for two main reasons: his leaving of gaps in his table, pointing the way to as yet undiscovered elements; and his ordering of table entries according to family behaviour rather than atomic mass [9]. None of this is to take away from Mendeleev’s seminal work, it is wholly appropriate that his name will always be linked with his most famous insight. Instead it is my intention is to demonstrate that the the course of true science never did run smooth [10].
The Johnson perspective
Since its creation – and during its many reformulations – the Periodic Table has acted as a pointer for many areas of scientific enquiry. Why do elements fall into families in this way? How many elements are there? Is it possible to achieve the Alchemists’ dream and transmute one element into another? However, the question which Professor Johnson’s diagram addresses is another one, Why is there such an abundance of elements and where did they all come from?
The term nucleosynthesis that appears in the title of this article covers processes by which different atoms are formed from either base nucleons (protons and neutrons) or the combination of smaller atoms. It is nucleosynthesis which attempts to answer the question we are now considering. There are different types.
Our current perspective on where everything in the observable Universe came from is of course the Big Bang [11]. This rather tidily accounts for the abundance of element 1, Hydrogen, and much of that of element 2, Helium. This is our first type of nucleosynthesis, Big Bang nucleosynthesis. However, it does not explain where all of the heavier elements came from [12]. The first part of the answer is from processes of nuclear fusion in stars. The most prevalent form of this is the fusion of Hydrogen to form Helium (accounting for the remaining Helium atoms), but this process continues creating heavier elements, albeit in ever decreasing quantities. This is stellar nucleosynthesis and refers to those elements created in stars during their normal lives.
While readers may be ready to accept the creation of these heavier elements in stars, an obvious question is How come they aren’t in stars any longer? The answer lies in what happens at the end of the life of a star. This is something that depends on a number of factors, but particularly its mass and also whether or not it is associated with another star, e.g. in a binary system.
Broadly speaking, higher mass stars tend to go out with a bang [13], lower mass ones with various kinds of whimpers. The exception to the latter is where the low mass star is coupled to another star, arrangements which can also lead to a considerable explosion as well [14]. Of whatever type, violent or passive, star deaths create all of the rest of the heavier elements. Supernovae are also responsible for releasing many heavy elements in to interstellar space, and this process is tagged explosive nucleosynthesis.
Into this relatively tidy model of nucleosynthesis intrudes the phenomenon of cosmic ray fission, by which cosmic rays [15] impact on heavier elements causing them to split into smaller constituents. We believe that this process is behind most of the Beryllium and Boron in the Universe as well as some of the Lithium. There are obviously other mechanisms at work like radioactive decay, but the vast majority of elements are created either in stars or during the death of stars.
I have elided many of the details of nucleosynthesis here, it is a complicated and evolving field. What Professor Johnson’s graphic achieves is to reflect current academic thinking around which elements are produced by which type of process. The diagram certainly highlights the fact that the genesis of the elements is a complex story. Perhaps less prosaically, it also encapulates Carl Sagan‘s famous aphorism, the one that Professor Johnson quotes at the beginning of her article and which I will use to close mine.
Lithium, Sodium, Potassium, Rubidium, Caesium and Francium (Hydrogen sometimes is shown as topping this list as well).
[3]
Helium, Argon, Neon, Krypton, Xenon and Radon.
[4]
Watch this space for an article pertinent to this very subject.
[5]
Isaac Newton on 15th February 1676. in a letter to Robert Hooke; but employing a turn of phrase which had been in use for many years.
[6]
And certainly the greatest scientist ever to be beheaded.
[7]
Döbereiner, J. W. (1829) “An Attempt to Group Elementary Substances according to Their Analogies”. Annalen der Physik und Chemie.
[8]
In truth somewhat earlier.
[9]
The emergence of atomic number as the organising principle behind the ordering of elements happened somewhat later, vindicating Mendeleev’s approach.
We have:
atomic mass ≅ number of protons in the nucleus of an element + number of neutrons
whereas:
atomic number = number of protons only
The number of neutrons can jump about between successive elements meaning that arranging them in order of atomic mass gives a different result from atomic number.
[10]
With apologies to The Bard.
[11]
I really can’t conceive that anyone who has read this far needs the Big Bang further expounded to them, but if so, then GIYF.
[12]
We think that the Big Bang also created some quantities of Lithium and several other heavier elements, as covered in Professor Johnson’s diagram.
Type-Ia supernovae are a phenomenon that allow us to accurately measure the size of the universe and how this is changing.
[15]
Cosmic rays are very high energy particles that originate from outside of the Solar System and consist mostly of very fast moving protons (aka Hydrogen nuclei) and other atomic nuclei similarly stripped of their electrons.
No neither my observations on the work of Kafka, nor that of Escher[1]. Instead some musings relating on how to transform a bare bones and unengaging chart into something that both captures the attention of the reader and better informs them of the message that the data displayed is relaying. Let’s consider an example:
Before:
After:
The two images above are both renderings of the same dataset, which tracks the degree of fragmentation of the Israeli parliament – the Knesset – over time [2]. They are clearly rather different and – I would argue – the latter makes it a lot easier to absorb information and thus to draw inferences.
Both are the work of Boris Gorelik a data scientist at Automattic, a company that is most well-known for creating freemium SAAS blogging platform, WordPress.com and open source blogging software, WordPress [3].
I have been a contented WordPress.com user since the inception of this blog back in November 2008, so it was with interest that I learnt that Automattic have their own data-focussed blog, Data for Breakfast, unsurprisingly hosted on WordPress.com. It was on Data for Breakfast that I found Boris’s article, Evolution of a Plot: Better Data Visualization, One Step at a Time. In this he takes the reader step by step through what he did to transform his data visualisation from the ugly duckling “before” exhibit to the beautiful swan “after” exhibit.
Boris is using Python and various related libraries to do his data visualisation work. Given that I stopped commercially programming sometime around 2009 (admittedly with a few lapses since), I typically use the much more quotidian Excel for most of the charts that appear on peterjamesthomas.com[4]. Sometimes, where warranted, I enhance these using Visio and / or PaintShop Pro.
For example, the three [5] visualisations featured in A Tale of Two [Brexit] Data Visualisations were produced this way. Despite the use of Calibri, which is probably something of a giveaway, I hope that none of these resembles a straight-out-of-the-box Excel graph [6].
UK Referendum on EU Membership – Percentage voting by age bracket (see notes)
UK Referendum on EU Membership – Numbers voting by age bracket (see notes)
UK Referendum on EU Membership – Number voting by age bracket (see notes)
While, in the above, I have not gone to the lengths that Boris has in transforming his initial and raw chart into something much more readable, I do my best to make my Excel charts look at least semi-professional. My reasoning is that, when the author of a chart has clearly put some effort into what their chart looks like and has at least attempted to consider how it will be read by people, then this is a strong signal that the subject matter merits some closer consideration.
Next time I develop a chart for posting on these pages, I may take Boris’s lead and also publish how I went about creating it.
Notes
[1]
Though the latter’s work has adorned these pages on several occasions and indeed appears in my seminar decks.
[2]
Boris has charted a metric derived from how many parties there have been and how many representatives of each. See his article itself for further background.
[3]
You can learn more about the latter at WordPress.org.
Click to download a larger PDF version in a new window.
In my last article, I looked at a couple of ways to visualise the outcome of the recent UK Referendum on Europen Union membership. There I was looking at how different visual representations highlight different attributes of data.
I’ve had a lot of positive feedback about my previous Brexit exhibits and I thought that I’d capture the zeitgeist by offering a further visual perspective, perhaps one more youthful than the venerable pie chart; namely an infographic. My attempt to produce one of these appears above and a full-size PDF version is also just a click away.
For caveats on the provenance of the data, please also see the previous article’s notes section.
Addendum
I have leveraged age group distributions from the Ascroft Polling organisation to create this exhibits. Other sites – notably the BBC – have done the same and my figures reconcile to the interpretations in other places. However, based on further analysis, I have some reason to think that either there are issues with the Ashcroft data, or that I have leveraged it in ways that the people who compiled it did not intend. Either way, the Ashcroft numbers lead to the conclusion that close to 100% of 55-64 year olds voted in the UK Referendum, which seems very, very unlikely. I have contacted the Ashcroft Polling organisation about this and will post any reply that I receive.
I’m continuing with the politics and data visualisation theme established in my last post. However, I’ll state up front that this is not a political article. I have assiduously stayed silent [on this blog at least] on the topic of my country’s future direction, both in the lead up to the 23rd June poll and in its aftermath. Instead, I’m going to restrict myself to making a point about data visualisation; both how it can inform and how it can mislead.
UK Referendum on EU Membership – Percentage voting by age bracket (see notes)
The exhibit above is my version of one that has appeared in various publications post referendum, both on-line and print. As is referenced, its two primary sources are the UK Electoral Commission and Lord Ashcroft’s polling organisation. The reason why there are two sources rather than one is explained in the notes section below.
With the caveats explained below, the above chart shows the generational divide apparent in the UK Referendum results. Those under 35 years old voted heavily for the UK to remain in the EU; those with ages between 35 and 44 voted to stay in pretty much exactly the proportion that the country as a whole voted to leave; and those over 45 years old voted increasingly heavily to leave as their years advanced.
One thing which is helpful about this exhibit is that it shows in what proportion each cohort voted. This means that the type of inferences I made in the previous paragraph leap off the page. It is pretty clear (visually) that there is a massive difference between how those aged 18-24 and those aged 65+ thought about the question in front of them in the polling booth. However, while the percentage based approach illuminates some things, it masks others. A cursory examination of the chart above might lead one to ask – based on the area covered by red rectangles – how it was that the Leave camp prevailed? To pursue an answer to this question, let’s consider the data with a slightly tweaked version of the same visualisation as below:
UK Referendum on EU Membership – Numbers voting by age bracket (see notes)
[Aside: The eagle-eyed amongst you may notice a discrepancy between the figures shown on the total bars above and the actual votes cast, which were respectively: Remain: 16,141k and Leave: 17,411k. Again see the notes section for an explanation of this.]
A shift from percentages to actual votes recorded casts some light on the overall picture. It now becomes clear that, while a large majority of 18-24 year olds voted to Remain, not many people in this category actually voted. Indeed while, according to the 2011 UK Census, the 18-24 year category makes up just under 12% of all people over 18 years old (not all of whom would necessarily be either eligible or registered to vote) the Ashcroft figures suggest that well under half of this group cast their ballot, compared to much higher turnouts for older voters (once more see the notes section for caveats).
This observation rather blunts the assertion that the old voted in ways that potentially disadvantaged the young; the young had every opportunity to make their voice heard more clearly, but didn’t take it. Reasons for this youthful disengagement from the political process are of course beyond the scope of this article.
However it is still hard (at least for the author’s eyes) to get the full picture from the second chart. In order to get a more visceral feeling for the dynamics of the vote, I have turned to the much maligned pie chart. I also chose to use the even less loved “exploded” version of this.
UK Referendum on EU Membership – Number voting by age bracket (see notes)
Here the weight of both the 65+ and 55+ Leave vote stands out as does the paucity of the overall 18-24 contribution; the only two pie slices too small to accommodate an internal data label. This exhibit immediately shows where the referendum was won and lost in a way that is not as easy to glean from a bar chart.
While I selected an exploded pie chart primarily for reasons of clarity, perhaps the fact that the resulting final exhibit brings to mind a shattered and reassembled Union Flag was also an artistic choice. Unfortunately, it seems that this resemblance has a high likelihood of proving all too prophetic in the coming months and years.
Addendum
I have leveraged age group distributions from the Ascroft Polling organisation to create these exhibits. Other sites – notably the BBC – have done the same and my figures reconcile to the interpretations in other places. However, based on further analysis, I have some reason to think that either there are issues with the Ashcroft data, or that I have leveraged it in ways that the people who compiled it did not intend. Either way, the Ashcroft numbers lead to the conclusion that close to 100% of 55-64 year olds voted in the UK Referendum, which seems very, very unlikely. I have contacted the Ashcroft Polling organisation about this and will post any reply that I receive.
– Peter James Thomas, 14th July 2016
Notes
Caveat: I am neither a professional political pollster, nor a statistician. Instead I’m a Pure Mathematician, with a basic understanding of some elements of both these areas. For this reason, the following commentary may not be 100% rigorous; however my hope is that it is nevertheless informative.
In the wake of the UK Referendum on EU membership, a lot of attempts were made to explain the result. Several of these used splits of the vote by demographic attributes to buttress the arguments that they were making. All of the exhibits in this article use age bands, one type of demographic indicator. Analyses posted elsewhere looked at things like the influence of the UK’s social grade classifications (A, B, C1 etc.) on voting patterns, the number of immigrants in a given part of the country, the relative prosperity of different areas and how this has changed over time. Other typical demographic dimensions might include gender, educational achievement or ethnicity.
However, no demographic information was captured as part of the UK referendum process. There is no central system which takes a unique voting ID and allocates attributes to it, allowing demographic dicing and slicing (to be sure a partial and optional version of this is carried out when people leave polling stations after a General Election, but this was not done during the recent referendum).
So, how do so many demographic analyses suddenly appear? To offer some sort of answer here, I’ll take you through how I built the data set behind the exhibits in this article. At the beginning I mentioned that I relied on two data sources, the actual election results published by the UK Electoral Commission and the results of polling carried out by Lord Ashcroft’s organisation. The latter covered interviews with 12,369 people selected to match what was anticipated to be the demographic characteristics of the actual people voting. As with most statistical work, properly selecting a sample with no inherent biases (e.g. one with the same proportion of people who are 65 years or older as in the wider electorate) is generally the key to accuracy of outcome.
Importantly demographic information is known about the sample (which may also be reweighted based on interview feedback) and it is by assuming that what holds true for the sample also holds true for the electorate that my charts are created. So if X% of 18-24 year olds in the sample voted Remain, the assumption is that X% of the total number of 18-24 year olds that voted will have done the same.
12,000 plus is a good sample size for this type of exercise and I have no reason to believe that Lord Ashcroft’s people were anything other than professional in selecting the sample members and adjusting their models accordingly. However this is not the same as having definitive information about everyone who voted. So every exhibit you see relating to the age of referendum voters, or their gender, or social classification is based on estimates. This is a fact that seldom seems to be emphasised by news organisations.
The size of Lord Ashchoft’s sample also explains why the total figures for Leave and Remain on my second exhibit are different to the voting numbers. This is because 5,949 / 12,369 = 48.096% (looking at the sample figures for Remain) whereas 16,141,241 / 33,551,983 = 48.108% (looking at the actual voting figures for Remain). Both figures round to 48.1%, but the small difference in the decimal expansions, when applied to 33 million people, yields a slightly different result.
In my earlier piece, Data Visualisation – A Scientific Treatment, I argued for more transparency in showing the inherent variability associated with the numbers spat out by statistical models. My specific call back then was for the use of error bars.
The FiveThirtyEight exhibit deals with this same challenge in a manner which I find elegant, clean and eminently digestible. It contains many different elements of information, but remains an exhibit whose meaning is easy to absorb. It’s an approach I will probably look to leverage myself next time I have a similar need.
This article is the second of three which address how to formulate an Information Strategy. I have written a number of other articles which touch on this subject[1] and have also spoken about the topic[2]. However I realised that I had never posted an in-depth review of this important area. This series of articles seeks to remedy this omission.
The first article, Part I – General Strategy, explored the nature of strategy, laid some foundations and presented a framework of questions which will need to be answered in order to formulate any general strategy. This chapter, Part II – Situational Analysis, explains how to adapt the first element of this general framework – The Situational Analysis – to creating an Information Strategy. In Part I, I likened formulating an Information Strategy to a journey, Part III – Completing the Strategy sees us reaching the destination by working through the rest of the general framework and showing how this can be used to produce a fully-formed Information Strategy.
As with all of my other articles, this essay is not intended as a recipe for success, a set of instructions which – if slavishly followed – will guarantee the desired outcome. Instead the reader is invited to view the following as a set of observations based on what I have learnt during a career in which the development of both Information Strategies and technology strategies in general have played a major role.
A Recap of the Strategic Framework
I closed Part I of this series by presenting a set of questions, the answers to which will facilitate the formation of any strategy. These have a geographic / journey theme and are as follows:
Where are we?
Where do we want to be instead and why?
How do we get there, how long will it take and what will it cost?
Will the trip be worth it?
What else can we do along the way?
In this article I will focus on how to answer the first question, Where are we? This is the province of a Situational Analysis. I will now move on from general strategy and begin to be specific about how to develop a Situational Analysis in the context of an overall Information Strategy.
But first a caveat: if the last article was prose-heavy, this one is question-heavy; the reader is warned!
Where are we? The anatomy of an Information Strategy’s Situational Analysis
If we take this question and, instead of aiming to plot our celestial coordinates, look to consider what it would mean in the context of an Information Strategy, then a number of further questions arise. Here are just a few examples of the types of questions that the strategist should investigate, broken down into five areas:
Business-focussed questions
What do business people use current information to do?
In their opinion, is current information adequate for this task and if not in what ways is it inadequate?
Are there any things that business people would like to do with information, but where the figures don’t exist or are not easily accessible?
How reliable and trusted is existing information, is it complete, accurate and suitably up-to-date?
If there are gaps in information provision, what are these and what is the impact of missing data?
How consistent is information provision, are business entities and calculated figures ambiguously labeled and can you get different answers to the same question in different places?
Is existing information available at the level that different people need, e.g. by department, country, customer, team or at at a transactional level?
Are there areas where business people believe that data is available, but no facilities exist to access this?
What is the extent of End User Computing, is this at an appropriate level and, if not, is poor information provision a driver for work in this area?
Related to this, are the needs of analytical staff catered for, or are information facilities targeted mostly at management reporting only?
How easy do business people view it as being to get changes made to information facilities, or to get access to the sort of ad hoc data sets necessary to support many business processes?
What training have business people received, what is the general level of awareness of existing information facilities and how easy is it for people to find what they need?
How intuitive are existing information facilities and how well-structured are menus which provide access to these?
Is current information provision something that is an indispensable part of getting work done, or at best an afterthought?
Design questions
How were existing information facilities created, who designed and built them and what level of business input was involved?
What are the key technical design components of the overall information architecture and how do they relate to each other?
If there is more than one existing information architecture (e.g. in different geographic locations or different business units), what are the differences between them?
How many different tools are used in various layers of the information architecture? E.g.
Databases
Extract Transform Load tools
Multidimensional data stores
Reporting and Analysis tools
Data Visualisation tools
Dashboard tools
Tools to provide information to applications or web-portals
What has been the role of data modeling in designing and developing information facilities?
If there is a target data model for the information facilities, is this fit for purpose and does it match business needs?
Has a business glossary been developed in parallel to the design of the information capabilities and if so is this linked to reporting layers?
What is the approach to master data and how is this working?
Technical questions
What are the key source systems and what are their types, are these integrated with each other in any way?
How does data flow between source systems?
Is there redundancy of data and can similar datasets in different systems get out of synch with each other, if so which are the master records?
How robust are information facilities, do they suffer outages, if so how often and what are the causes?
Are any issues experienced in making changes to information facilities, either extended development time, or post-implementation failures?
Are there similar issues related to the time taken to fix information facilities when they go wrong?
Are various development tools integrated with each other in a way that helps developers and makes code more rigourous?
How are errors in input data handled and how robust are information facilities in the face of these challenges?
How well-optimised is the regular conversion of data into information?
How well do information facilities cope with changes to business entities (e.g. the merger of two customers)?
Is the IT infrastructure(s) underpinning information facilities suitable for current data volumes, what about future data volumes?
Is there a need for redundancy in the IT infrastructure supporting information facilities, if so, how is this delivered?
Are suitable arrangements in place for disaster recovery?
Process questions
Is there an overall development methodology applied to the creation of information facilities?[3]
If so, is it adhered to and is it fit for purpose?
What controls are applied to the development of new code and data structures?
How are requests for new facilities estimated and prioritised?
How do business requirements get translated into what developers actually do and is this process working?
Is the level, content and completeness of documentation suitable, is it up-to-date and readily accessible to all team members?
What is the approach to testing new information facilities?
Are there any formal arrangements for Data Governance and any initiatives to drive improvements in data quality?
How are day-to-day support and operational matters dealt with and by whom?
Information Team questions
Is there a single Information Team or many, if many, how do they collaborate and share best practice?
What is the demand for work required of the existing team(s) and how does this relate to their capacity for delivery?
What are the skills of current team members and how do these complement each other?
Are there any obvious skill gaps or important missing roles?
How do information people relate to other parts of IT and to their business colleagues?
How is the information team(s) viewed by their stakeholders in terms of capability, knowledge and attitude?
An Approach to Geolocation
So that’s a long list of questions[4], to add to the list: what is the best way of answering them? Of course it may be that there is existing documentation which can help in some areas, however the majority of questions are going to be answered via the expedient of talking to people. While this may appear to be a simple approach, if these discussions are going to result in an accurate and relevant Situational Analysis, then how to proceed needs to be thought about up-front and work needs to be properly structured.
Business conversations
A challenge here is the range and number of people[5]. It is of course crucial to start with the people who consume information. These discussions would ideally allow the strategist to get a feeling for what different business people do and how they do it. This would cover their products/services, the markets that they operate in and the competitive landscape they face. With some idea of these matters established, the next item is their needs for information and how well these are met at present. Together feedback in these areas will begin to help to shape answers to some of the business-focussed questions referenced above (and to provide pointers to guide investigations in other areas). However it is not as simple an equation as:
Talk to Business People = Answer all Business-focussed Questions
The feedback from different people will not be identical, variations may be driven by their personal experience, how long they have been at the company and what part of its operations they work in. Different people will also approach their work in different ways, some will want to be very numerically focussed in decision-making, others will rely more on experience and relationships. Also even getting information out of people in the first place is a skill in itself; it is a capital mistake for even the best analyst to theorise before they have data[6].
This heterogeneity means that one challenge in writing the business-focussed component of a Situational Analysis within an overall Information Strategy is sifting through the different feedback looking for items which people agree upon, or patterns in what people said and the frequency with which different people made similar points. This work is non-trivial and there is no real substitute for experience. However, one thing that I would suggest can help is to formally document discussions with business people. This has a number of advantages, such as being able to run this past them to check the accuracy and completeness of your notes[7] and being able to defend any findings as based on actual fact. However, documenting meetings also facilitates the analysis and synthesis process described above. These meeting notes can be read and re-read (or shared between a number of people collectively engaged in the strategy formulation process) and – when draft findings have been developed – these can be compared to the original source material to ensure consistency and completeness.
IT conversations
Depending on circumstances, talking to business people can often be the largest activity and will do most to formulate proposals that will appear in other parts of the Information Strategy. However the other types of questions also need to be considered and parallel discussions with general IT people are a prerequisite. An objective here is for the strategist to understand (and perhaps document) the overall IT landscape and how this flows into current information capabilities. Such a review can also help to identify mismatches between business aspirations and system capabilities; there may be a desire to report on data which is captured nowhere in the organisation for example.
The final tranche of discussions need to be with the information professionals who have built the current information landscape (assuming that they are still at the company, if not then the people to target are those who maintain information facilities). There can sometimes be an element of defensiveness to be overcome in such discussions, but equally no one will have a better idea about the challenges with existing information provision than the people who deal with this area day in and day out. It is worth taking the time to understand their thoughts and opinions. With both of these groups of IT people, formally documented notes and/or schematics are just as valuable as with the business people and for the same reasons.
Rinse and Repeat
The above conversations have been described sequentially, but some element of them will probably be in parallel. Equally the process is likely to be somewhat iterative. It is perhaps a good idea to meet with a subset of business people first, draw some very preliminary conclusions from these discussions and then hold some initial meetings with various IT people to both gather more information and potentially kick the tyres on your embryonic findings. Sometimes after having done a lot of business interviews, it is also worth circling back to the first cohort both to ask some different questions based on later feedback and also to validate the findings which you are hopefully beginning to refine by now.
Of course a danger here is that you could spend an essentially limitless time engaging with people and not ever landing your Situational Analysis; in particular person A may suggest what a good idea it would be for you to also meet with person B and person C (and so on exponentially). The best way to guard against this is time-boxing. Give your self a deadline, perhaps arrange for a presentation of an initial Situational Analysis to an audience at a point in the not-so-distance future. This will help to focus your efforts. Of course mentioning a presentation, or at least some sort of abridged Situational Analysis, brings up the idea of how to summarise the detailed information that you have uncovered through the process described above. This is the subject of the final section of this article.
In Summary
I will talk further about how to summarise findings and recommendations in Part III, for now I wanted to focus on just two aspects of this. First a mechanism to begin to identify areas of concern and second a simple visual way to present the key elements of an information-focussed Situational Analysis in a relatively simple exhibit.
Sorting the wheat from the chaff
To an extent, sifting through large amounts of feedback from a number of people is one way in which good IT professionals earn their money. Again experience is the most valuable tool to apply in this situation. However, I would suggest some intermediate steps would also be useful here both to the novice and the seasoned professional. If you have extensive primary material from your discussions with a variety of people and have begun to discern some common themes through this process, then – rather than trying to progress immediately to an overall summary – I would recommend writing notes around each of these common themes as a good place to start. These notes may be only for your own purposes, or they may be something that you also later choose to circulate as additional information; if you take the latter approach, then bear the eventual audience in mind while writing. Probably while you are composing these intermediate-level notes a number of things will happen. First it may occur to you that some sections could be split to more precisely target the issues. Equally other sections may overlap somewhat and could benefit from being merged. Also you may come to realise that you have overlooked some areas and need to address these.
Whatever else is happening, this approach is likely to give your subconscious some time to chew over the material in parallel. It is for this reason that sometimes the strategist will wake at night with an insight that had previously eluded them. Whether or not the subconscious contributes this dramatically, this rather messy and organic process will leave you with a number of paragraphs (or maybe pages) on a handful of themes. This can then form the basis of the more summary exhibit which I describe in the next section; namely a scorecard.
An Information Provision Scorecard
Of course a scorecard about the state of information provision approaches levels of self-reference that Douglas R Hofstadter[8] would be proud of. I would suggest that such a scorecard could be devised by thinking about each of the common themes that have arisen, considering each of the areas of questioning described above (business, design, technical, process and team), or perhaps a combination of both. The example scorecard which I provide above uses the areas of questions as its intermediate level. These are each split out into a number of sub-categories (these will vary from situation to situation and hence I have not attempted to provide actual sub-category names). A score can be allocated (based on your research) to each of these on some scale (the example uses a 5 point one) and these base figures can be rolled up to get a score for each of the intermediate categories. These can then be further summarised to give a single, overall score [9].
While a data visualisation such as the one presented here may be a good way to present overall findings, it is important that this can be tied back to the notes that have been compiled during the analysis. Sometimes such scores will be challenged and it is important that they are based in fact and can thus be defended.
Next steps
Of course your scorecard, or overall Situational Analysis, could tell you that all is well. If this is the case, then our work here may be done[10]. If however the Situational Analysis reveals areas where improvements can be made, or if there is a desire to move the organisation forward in a way that requires changes to information provision, then thought must be given to either what can be done to remediate problems or what is necessary to seize opportunities; most often a mixture of both. Considering these questions will be the subject of the final article in this series, Forming an Information Strategy: Part III – Completing the Strategy.
Addendum
When I published the first part of this series, I received an interesting comment from Gary Nuttall, Head of Business Intelligence at Chaucer Syndicates (you can view Gary’s profile on LinkedIn and he posts as @gpn01 on Twitter). I reproduce an extract from this verbatim below:
[When considering questions such as “Where are we?”] one thing I’d add, which for smaller organisations may not be relevant, is to consider who the “we” is (are?). For a multinational it can be worth scoping out whether the strategy is for the legal entity or group of companies, does it include the ultimate parent, etc. It can also help in determining the culture of the enterprise too which will help to shape the size, depth and span of the strategy too – for some companies a two pager is more than enough for others a 200 pager would be considered more appropriate.
I think that this is a valuable additional perspective and I thank Gary for providing this insightful and helpful feedback.
There are a whole raft of sub-questions here and I don’t propose to be exhaustive in this article.
[4]
In practice its at best a representative subset of the questions that would need to be answered to assemble a robust situational analysis.
[5]
To get some perspective on the potential range of business people it is necessary to engage in such a process, again see the aforementioned Developing an international BI strategy.
You can try to be cute here and weight scores before rolling them up. In practice this is seldom helpful and can give the impression that the precision of scoring is higher than can ever actually be the case. Judgement also needs to be exercised in determining which graphic to use to best represent a rolled up score as these will seldom precisely equal the fractions selected; quarters in this example. The strategist should think about whether a rounded-up or rounded-down summary score is more representative of reality as pure arithmetic may not suffice in all cases.
[10]
There remains the possibility that the current situation is well-aligned with current business practices, but will have problems supporting future ones. In this case perhaps a situational analysis is less useful, unless this is comparing to some desired future state (of which more in the next chapter).
As a picture is said to paint a thousand words, I’ll (mostly) leave it to Scienceogram’s infographic to deliver the message.
However, The Center for Responsive Politics (I have no idea whether or not they have a political affiliation, they claim to be nonpartisan) estimates the cost of the recent US Congressional elections at around $3.67 bn (€2.93 bn). I found a lower (but still rather astonishing) figure of $1.34 bn (€1.07 bn) at the Federal Election Commission web-site, but suspect that this number excludes Political Action Committees and their like.
To make a European comparisson to a European space project, the Common Agriculture Policy cost €57.5 bn ($72.0 bn) in 2013 according to the BBC. Given that Rosetta’s costs were spread over nearly 20 years, it makes sense to move the decimal point rightwards one place in both the euro and dollar figures and then to double the resulting numbers before making comparisons (this is left as an exercise for the reader).
Of course I am well aware that a quick Google could easily produce figures (such as how many meals, or vaccinations, or so on you could get for €1.4 bn) making points that are entirely antipodal to the ones presented. At the end of the day we landed on a comet and will – fingers crossed – begin to understand more about the formation of the Solar System and potentially Life on Earth itself as a result. Whether or not you think that is good value for money probably depends mostly on what sort of person you are. As I relate in a previous article, infographics only get you so far.
Scienceogram provides précis [correct plural] of UK science spending, giving overviews of how investment in science compares to the size of the problems it’s seeking to solve.
The above diagram was compiled by Florence Nightingale, who was – according to The Font – “a celebrated English social reformer and statistician, and the founder of modern nursing”. It is gratifying to see her less high-profile role as a number-cruncher acknowledged up-front and central; particularly as she died in 1910, eight years before women in the UK were first allowed to vote and eighteen before universal suffrage. This diagram is one of two which are generally cited in any article on Data Visualisation. The other is Charles Minard’s exhibit detailing the advance on, and retreat from, Moscow of Napoleon Bonaparte’s Grande Armée in 1812 (Data Visualisation had a military genesis in common with – amongst many other things – the internet). I’ll leave the reader to look at this second famous diagram if they want to; it’s just a click away.
While there are more elements of numeric information in Minard’s work (what we would now call measures), there is a differentiating point to be made about Nightingale’s diagram. This is that it was specifically produced to aid members of the British parliament in their understanding of conditions during the Crimean War (1853-56); particularly given that such non-specialists had struggled to understand traditional (and technical) statistical reports. Again, rather remarkably, we have here a scenario where the great and the good were listening to the opinions of someone who was barred from voting on the basis of lacking a Y chromosome. Perhaps more pertinently to this blog, this scenario relates to one of the objectives of modern-day Data Visualisation in business; namely explaining complex issues, which don’t leap off of a page of figures, to busy decision makers, some of whom may not be experts in the specific subject area (another is of course allowing the expert to discern less than obvious patterns in large or complex sets of data). Fortunately most business decision makers don’t have to grapple with the progression in number of “deaths from Preventible or Mitigable Zymotic diseases” versus ”deaths from wounds” over time, but the point remains.
Data Visualisation in one branch of Science
Coming much more up to date, I wanted to consider a modern example of Data Visualisation. As with Nightingale’s work, this is not business-focused, but contains some elements which should be pertinent to the professional considering the creation of diagrams in a business context. The specific area I will now consider is Structural Biology. For the incognoscenti (no advert for IBM intended!), this area of science is focussed on determining the three-dimensional shape of biologically relevant macro-molecules, most frequently proteins or protein complexes. The history of Structural Biology is intertwined with the development of X-ray crystallography by Max von Laue and father and son team William Henry and William Lawrence Bragg; its subsequent application to organic molecules by a host of pioneers including Dorothy Crowfoot Hodgkin, John Kendrew and Max Perutz; and – of greatest resonance to the general population – Francis Crick, Rosalind Franklin, James Watson and Maurice Wilkins’s joint determination of the structure of DNA in 1953.
X-ray diffraction image of the double helix structure of the DNA molecule, taken 1952 by Raymond Gosling, commonly referred to as “Photo 51”, during work by Rosalind Franklin on the structure of DNA
While the masses of data gathered in modern X-ray crystallography needs computer software to extrapolate them to physical structures, things were more accessible in 1953. Indeed, it could be argued that Gosling and Franklin’s famous image, its characteristic “X” suggestive of two helices and thus driving Crick and Watson’s model building, is another notable example of Data Visualisation; at least in the sense of a picture (rather than numbers) suggesting some underlying truth. In this case, the production of Photo 51 led directly to the creation of the even more iconic image below (which was drawn by Francis Crick’s wife Odile and appeared in his and Watson’s seminal Nature paper[1]):
It is probably fair to say that the visualisation of data which is displayed above has had something of an impact on humankind in the fifty years since it was first drawn.
Modern Structural Biology
Today, X-ray crystallography is one of many tools available to the structural biologist with other approaches including Nuclear Magnetic Resonance Spectroscopy, Electron Microscopy and a range of biophysical techniques which I will not detain the reader by listing. The cutting edge is probably represented by the X-ray Free Electron Laser, a device originally created by repurposing the linear accelerators of the previous generation’s particle physicists. In general Structural Biology has historically sat at an intersection of Physics and Biology.
However, before trips to synchrotrons can be planned, the Structural Biologist often faces the prospect of stabilising their protein of interest, ensuring that they can generate sufficient quantities of it, successfully isolating the protein and finally generating crystals of appropriate quality. This process often consumes years, in some cases decades. As with most forms of human endeavour, there are few short-cuts and the outcome is at least loosely correlated to the amount of time and effort applied (though sadly with no guarantee that hard work will always be rewarded).
From the general to the specific
At this point I should declare a personal interest, the example of Data Visualisation which I am going to consider is taken from a paper recently accepted by the Journal of Molecular Biology (JMB) and of which my wife is the first author[2]. Before looking at this exhibit, it’s worth a brief detour to provide some context.
In recent decades, the exponential growth in the breadth and depth of scientific knowledge (plus of course the velocity with which this can be disseminated), coupled with the increase in the range and complexity of techniques and equipment employed, has led to the emergence of specialists. In turn this means that, in a manner analogous to the early production lines, science has become a very collaborative activity; expert in stage one hands over the fruits of their labour to expert in stage two and so on. For this reason the typical scientific paper (and certainly those in Structural Biology) will have several authors, often spread across multiple laboratory groups and frequently in different countries. By way of example the previous paper my wife worked on had 16 authors (including a Nobel Laureate[3]). In this context, the fact the paper I will now reference was authored by just my wife and her group leader is noteworthy.
The reader may at this point be relieved to learn that I am not going to endeavour to explain the subject matter of my wife’s paper, nor the general area of biology to which it pertains (the interested are recommended to Google “membrane proteins” or “G Protein Coupled Receptors” as a starting point). Instead let’s take a look at one of the exhibits.
The above diagram (in common with Nightingale’s much earlier one) attempts to show a connection between sets of data, rather than just the data itself. I’ll elide the scientific specifics here and focus on more general issues.
First the grey upper section with the darker blots on it – which is labelled (a) – is an image of a biological assay called a Western Blot (for the interested, details can be viewed here); each vertical column (labelled at the top of the diagram) represents a sub-experiment on protein drawn from a specific sample of cells. The vertical position of a blot indicates the size of the molecules found within it (in kilodaltons); the intensity of a given blot indicates how much of the substance is present. Aside from the headings and labels, the upper part of the figure is a photographic image and so essentially analogue data[4]. So, in summary, this upper section represents the findings from one set of experiments.
At the bottom – and labelled (b) – appears an artefact familiar to anyone in business, a bar-graph. This presents results from a parallel experiment on samples of protein from the same cells (for the interested, this set of data relates to degree to which proteins in the samples bind to a specific radiolabelled ligand). The second set of data is taken from what I might refer to as a “counting machine” and is thus essentially digital. To be 100% clear, the bar chart is not a representation of the data in the upper part of the diagram, it pertains to results from a second experiment on the same samples. As indicated by the labelling, for a given sample, the column in the bar chart (b) is aligned with the column in the Western Blot above (a), connecting the two different sets of results.
Taken together the upper and lower sections[5] establish a relationship between the two sets of data. Again I’ll skip on the specifics, but the general point is that while the Western Blot (a) and the binding assay (b) tell us the same story, the Western Blot is a much more straightforward and speedy procedure. The relationship that the paper establishes means that just the Western Blot can be used to perform a simple new assay which will save significant time and effort for people engaged in the determination of the structures of membrane proteins; a valuable new insight. Clearly the relationships that have been inferred could equally have been presented in a tabular form instead and be just as relevant. It is however testament to the more atavistic side of humans that – in common with many relationships between data – a picture says it more surely and (to mix a metaphor) more viscerally. This is the essence of Data Visualisation.
What learnings can Scientific Data Visualisation provide to Business?
Using the JMB exhibit above, I wanted to now make some more general observations and consider a few questions which arise out of comparing scientific and business approaches to Data Visualisation. I think that many of these points are pertinent to analysis in general.
Normalisation
Broadly, normalisation[6] consists of defining results in relation to some established yardstick (or set of yardsticks); displaying relative, as opposed to absolute, numbers. In the JMB exhibit above, the amount of protein solubilised in various detergents is shown with reference to the un-solubilised amount found in native membranes; these reference figures appear as 100% columns to the right and left extremes of the diagram.
The most common usage of normalisation in business is growth percentages. Here the fact that London business has grown by 5% can be compared to Copenhagen having grown by 10% despite total London business being 20-times the volume of Copenhagen’s. A related business example, depending on implementation details, could be comparing foreign currency amounts at a fixed exchange rate to remove the impact of currency fluctuation.
Normalised figures are very typical in science, but, aside from the growth example mentioned above, considerably less prevalent in business. In both avenues of human endeavour, the approach should be used with caution; something that increases 200% from a very small starting point may not be relevant, be that the result of an experiment or weekly sales figures. Bearing this in mind, normalisation is often essential when looking to present data of different orders on the same graph[7]; the alternative often being that smaller data is swamped by larger, not always what is desirable.
Controls
I’ll use an anecdote to illustrate this area from a business perspective. Imagine an organisation which (as you would expect) tracks the volume of sales of a product or service it provides via a number of outlets. Imagine further that it launches some sort of promotion, perhaps valid only for a week, and notices an uptick in these sales. It is extremely tempting to state that the promotion has resulted in increased sales[8].
However this cannot always be stated with certainty. Sales may have increased for some totally unrelated reason such as (depending on what is being sold) good or bad weather, a competitor increasing prices or closing one or more of their comparable outlets and so on. Equally perniciously, the promotion maybe have simply moved sales in time – people may have been going to buy the organisation’s product or service in the weeks following a promotion, but have brought the expenditure forward to take advantage of it. If this is indeed the case, an uptick in sales may well be due to the impact of a promotion, but will be offset by a subsequent decrease.
In science, it is this type of problem that the concept of control tests is designed to combat. As well as testing a result in the presence of substance or condition X, a well-designed scientific experiment will also be carried out in the absence of substance or condition X, the latter being the control. In the JMB exhibit above, the controls appear in the columns with white labels.
There are ways to make the business “experiment” I refer to above more scientific of course. In retail business, the current focus on loyalty cards can help, assuming that these can be associated with the relevant transactions. If the business is on-line then historical records of purchasing behaviour can be similarly referenced. In the above example, the organisation could decide to offer the promotion at only a subset of the its outlets, allowing a comparison to those where no promotion applied. This approach may improve rigour somewhat, but of course it does not cater for purchases transferred from a non-promotion outlet to a promotion one (unless a whole raft of assumptions are made). There are entire industries devoted to helping businesses deal with these rather messy scenarios, but it is probably fair to say that it is normally easier to devise and carry out control tests in science.
The general take away here is that a graph which shows some change in a business output (say sales or profit) correlated to some change in a business input (e.g. a promotion, a new product launch, or a price cut) would carry a lot more weight if it also provided some measure of what would have happened without the change in input (not that this is always easy to measure).
Rigour and Scrutiny
I mention in the footnotes that the JMB paper in question includes versions of the exhibit presented above for four other membrane proteins, this being in order to firmly establish a connection. Looking at just the figure I have included here, each element of the data presented in the lower bar-graph area is based on duplicated or triplicated tests, with average results (and error bars – see the next section) being shown. When you consider that upwards of three months’ preparatory work could have gone into any of these elements and that a mistake at any stage during this time would have rendered the work useless, some impression of the level of rigour involved emerges. The result of this assiduous work is that the authors can be confident that the exhibits they have developed are accurate and will stand up to external scrutiny. Of course such external scrutiny is a key part of the scientific process and the manuscript of the paper was reviewed extensively by independent experts before being accepted for publication.
In the business world, such external scrutiny tends to apply most frequently to publicly published figures (such as audited Financial Accounts); of course external financial analysts also will look to dig into figures. There may be some internal scrutiny around both the additional numbers used to run the business and the graphical representations of these (and indeed some companies take this area very seriously), but not every internal KPI is vetted the way that the report and accounts are. Particularly in the area of Data Visualisation, there is a tension here. Graphical exhibits can have a lot of impact if they relate to the current situation or present trends; contrawise if they are substantially out-of-date, people may question their relevance. There is sometimes the expectation that a dashboard is just like its aeronautical counterpart, showing real-time information about what is going on now[9]. However a lot of the value of Data Visualisation is not about the here and now so much as trends and explanations of the factors behind the here and now. A well-thought out graph can tell a very powerful story, more powerful for most people than a table of figures. However a striking graph based on poor quality data, data which has been combined in the wrong way, or even – as sometimes happens – the wrong datasets entirely, can tell a very misleading story and lead to the wrong decisions being taken.
I am not for a moment suggesting here that every exhibit produced using Data Visualisation tools must be subject to months of scrutiny. As referenced above, in the hands of an expert such tools have the value of sometimes quickly uncovering hidden themes or factors. However, I would argue that – as in science – if the analyst involved finds something truly striking, an association which he or she feels will really resonate with senior business people, then double- or even triple-checking the data would be advisable. Asking a colleague to run their eye over the findings and to then probe for any obvious mistakes or weaknesses sounds like an appropriate next step. Internal Data Visualisations are never going to be subject to peer-review, however their value in taking sound business decisions will be increased substantially if their production reflects at least some of the rigour and scrutiny which are staples of the scientific method.
Dealing with Uncertainty
In the previous section I referred to the error bars appearing on the JMB figure above. Error bars are acknowledgements that what is being represented is variable and they indicate the extent of such variability. When dealing with a physical system (be that mechanical or – as in the case above – biological), behaviour is subject to many factors, not all of which can be eliminated or adjusted for and not all of which are predictable. This means that repeating an experiment under ostensibly identical conditions can lead to different results[10]. If the experiment is well-designed and if the experimenter is diligent, then such variability is minimised, but never eliminated. Error bars are a recognition of this fundamental aspect of the universe as we understand it.
While de rigueur in science, error bars seldom make an appearance in business, even – in my experience – in estimates of business measures which emerge from statistical analyses[11]. Even outside the realm of statistically generated figures, more business measures are subject to uncertainty than might initially be thought. An example here might be a comparison (perhaps as part of the externally scrutinised report and accounts) of the current quarter’s sales to the previous one (or the same one last year). In companies where sales may be tied to – for example – the number of outlets, care is paid to making these figures like-for-like. This might include only showing numbers for outlets which were in operation in the prior period and remain in operation now (i.e. excluding sales from both closed outlets or newly opened ones). However, outside the area of high-volume low-value sales where the Law of Large Numbers[12] rules, other factors could substantially skew a given quarter’s results for many organisations. Something as simple as a key customer delaying a purchase (so that it fell in Q3 this year instead of Q2 last) could have a large impact on quarterly comparisons. Again companies will sometimes look to include adjustments to cater for such timing or related issues, but this cannot be a precise process.
The main point I am making here is that many aspects of the information produced in companies is uncertain. The cash transactions in a quarter are of course the cash transactions in a quarter, but the above scenario suggests that they may not always 100% reflect actual business conditions (and you cannot adjust for everything). Equally where you get in to figures that would be part of most companies’ financial results, outstanding receivables and allowance for bad debts, the spectre of uncertainty arises again without a statistical model in sight. In many industries, regulators are pushing for companies to include more forward-looking estimates of future assets and liabilities in their Financials. While this may be a sensible reaction to recent economic crises, the approach inevitably leads to more figures being produced from models. Even when these models are subject to external review, as is the case with most regulatory-focussed ones, they are still models and there will be uncertainty around the numbers that they generate. While companies will often provide a range of estimates for things like guidance on future earnings per share, providing a range of estimates for historical financial exhibits is not really a mainstream activity.
Which perhaps gets me back to the subject of error bars on graphs. In general I think that their presence in Data Visualisations can only add value, not subtract it. In my article entitled Limitations of Business Intelligence I include the following passage which contains an exhibit showing how the Bank of England approaches communicating the uncertainty inevitably associated with its inflation estimates:
Business Intelligence is not a crystal ball, Predictive Analytics is not a crystal ball either. They are extremely useful tools […] but they are not universal panaceas.
An inflation prediction from The Bank of England Illustrating the fairly obvious fact that uncertainty increases in proportion to time from now.
[…] Statistical models will never give you precise answers to what will happen in the future – a range of outcomes, together with probabilities associated with each is the best you can hope for (see above). Predictive Analytics will not make you prescient, instead it can provide you with useful guidance, so long as you remember it is a prediction, not fact.
While I can’t see them figuring in formal financial statements any time soon, perhaps there is a case for more business Data Visualisations to include error bars.
In Summary
So, as is often the case, I have embarked on a journey. I started with an early example of Data Visualisation, diverted in to a particular branch of science with which I have some familiarity and hopefully returned, again as is often the case, to make some points which I think are pertinent to both the Business Intelligence practitioner and the consumers (and indeed commissioners) of Data Visualisations. Back in “All that glisters is not gold” – some thoughts on dashboards I made some more general comments about the best Data Visualisations having strong informational foundations underpinning them. While this observation remains true, I do see a lot of value in numerically able and intellectually curious people using Data Visualisation tools to quickly make connections which had not been made before and to tease out patterns from large data sets. In addition there can be great value in using Data Visualisation to present more quotidian information in a more easily digestible manner. However I also think that some of the learnings from science which I have presented in this article suggest that – as with all powerful tools – appropriate discretion on the part of the people generating Data Visualisation exhibits and on the part of the people consuming such content would be prudent. In particular the business equivalents of establishing controls, applying suitable rigour to data generation / combination and including information about uncertainty on exhibits where appropriate are all things which can help make Data Visualisation more honest and thus – at least in my opinion – more valuable.
The list of scientists involved in the development of X-ray Crystallography and Structural Biology which was presented earlier in the text encompasses a further nine such laureates (four of whom worked at my wife’s current research institute), though sadly this number does not include Rosalind Franklin. Over 20 Nobel Prizes have been awarded to people working in the field of Structural Biology, you can view an interactive time line of these here.
[4]
The intensity, size and position of blots are often digitised by specialist software, but this is an aside for our purposes.
[5]
Plus four other analogous exhibits which appear in the paper and relate to different proteins.
[6]
Normalisation has a precise mathematical meaning, actually (somewhat ironically for that most precise of activities) more than one. Here I am using the term more loosely.
[7]
That’s assuming you don’t want to get into log scales, something I have only come across once in over 25 years in business.
[8]
The uptick could be as compared to the week before, or to some other week (e.g. the same one last year or last month maybe) or versus an annual weekly average. The change is what is important here, not what the change is with respect to.
[9]
Of course some element of real-time information is indeed both feasible and desirable; for more analytic work (which encompasses many aspects of Data Visualisation) what is normally more important is sufficient historical data of good enough quality.
[10]
Anyone interested in some of the reasons for this is directed to my earlier article Patterns patterns everywhere.
Yesterday I was tweeting quotes from Poe and blogging lines attributed to Heraclitus. Today I’m moving on to Shakespeare. Kudos to anyone posting a comment pointing out the second quote that appears later in the text.
Introduction
Dashboards are all the rage at present. The basic idea is that they provide a way to quickly see what is happening, without getting lost in a sea of numbers. There are lots of different technologies out there that can help with dashboards. These range from parts of the product suites of all the main BI vendors, through boutique products dedicated to the area, all the way to simply using Java to write your own.
A lot of effort needs to go into how a dashboard is presented. The information really does need to leap off the screen, it is important that it looks professional. People are used to seeing well-designed sites on the web and if your corporate dashboard looks like it is only one step removed from Excel charts, you may have a problem. While engaging a design firm to help craft a dashboard might be overkill, it helps to get some graphic design input. I have been lucky enough over the years to have had people on my teams with experience in this area. They have mostly been hobbyists, but they had enough flair and enough of an aesthetic taste to make a difference.
However, echoing my comments on BI tools in general, I think an attractive looking dashboard is really only the icing on the cake. The cake itself has two main other ingredients:
The actual figures that it presents (and how well they have been chosen) and
The Information Architecture that underpins them
I’ll now consider the importance of these two areas.
Choosing the KPIs
The acronym KPI is bandied about with enormous vigour in the BI community. Sometimes what the ‘K’ stands for can get a bit lost in the cacophony. Stepping back from dashboards for a few minutes, I want to focus on the measures that you have in your general business intelligence applications such as analysis cubes. Things like: sales revenue, units sold, growth, head count, profit and so on.
[Note: If you don’t like BI buzzwords, please feel free to read “figures”, or “numbers” where ever you see “measures”. I may attempt to provide my own definitions of some of these terms in the future as the Wikipedia entries aren’t always that illuminating.]
When you have built a Data Mart for a particular subject area and are looking to develop one or more cubes based on this, you may well have a myriad of measures to select from. In some of the earliest prototype cubes that my teams built, we made the mistake of having too many measures. The same observation equally applied to the number of dimensions (things that you want to slice and dice the measures by, e.g. geography, line of business, product, customer etc.). Having too many measures and dimensions led to a cube that was cumbersome, difficult to navigate and where the business purpose was less that crystal clear. These are all cardinal sins, but the last is the worst as I have referred to elsewhere. The clear objective is to cut down on both the figures and the business attributes that you want to look at them by. We set a rule (which we did break a couple of times for specialist applications) of generally having no more than ten measures and ten dimensions in a cube and ideally having less.
Well this all sounds great, the problem – and the reason for this diversion away from dashboards – is which measures do you keep and which do you drop. Here there is no real alternative to lots of discussions with business partners, building multiple prototypes to test out different combinations and, ultimately, accepting that you might make some mis-steps in your first release and need to revisit the area after it has been “shaken down” by real business use. I won’t delve into this particular process any deeper now. Suffice it to say that choosing which measures to include in a cube it is both an area that is important to get right and one in which it is all to easy to make mistakes.
So, retuning to our main discussion, if picking measures at the level of an analysis cube is hard, just how hard is it to pick KPIs for a dashboard. I recall a conversation with the CEO of a large organisation in which he basically told me to just pick the six most important figure and put them on a dashboard (with the clear implication that sooner would be rather better than later). After I had explained that the view of the CEO in this area was of paramount importance and that his input on which figures to use would be very valuable, we began to talk about what should be in and what should be out. After a period of going round in circles, I at least managed to convey the fact that this was not a trivial decision.
What you want with the KPIs on a dashboard is that they are genuinely key and that you can actually tell something from graphing them. The exercise in determining which figures to use and how to present them was a lengthy one, but very worthwhile. You need to rigorously apply the “so what?” test – what action will people take based on the trends and indicators that are presented to them. In the end we went for simplicity, with a focus on growth.
There was a map showing how each country was doing against plan; colour-coded red, amber and green according to their results. There were graphs comparing revenue to budget by month and the cumulative position and there was a break-down by business unit. The only to elements of interaction were to filter for a region or country and a business unit or line of business. Any further analysis required pulling up an underlying cube (actually we integrated the cube with the dashboard so that context was maintained moving from one to the other – this was not so easy as the dashboard and cube tools, while from the same vendor, were on two different major release numbers).
There were many iterations of the dashboard, but the one we eventually went live with received general acclaim. I’m not sure what we could have done differently to shorten the process.
Where does the data come from?
A dashboard without an underlying Information Architecture
The same range of dashboard tools that I mention in the introduction are of course mostly capable of sourcing their data from pretty much anywhere. If the goal is to build a dashboard, then maybe it is tempting to do this as quickly as possible, based on whatever data sources are to hand (as in the diagram above). This is probably the quickest way to produce a dashboard, but it is unlikely to produce something that is used much, tells people anything useful, or adds any value. Why do I say this?
Well the problem with this approach is that all you are doing is reflecting what is likely to be a somewhat fragmented (and maybe even chaotic) set of information tools. Out of your sources, is there a unique place to go to get a definitive value for measure A? Do the various different sources hold data in the same way and calculate values using the same formulae? Do sources overlap (either duplicating data, or function), if so, which ones do you use? Do different sources get refreshed with the same frequency and do they treat currency the same way? Are customers and products defined consistently everywhere?
A dashboad underpinned by a proper Information Architecture
Leaving issues like these unresolved is a sure way to perpetuate a poor state of information. They are best addressed by establishing a wider information architecture (a simplified diagram of which appears above). I am not going to go into all of the benefits of such an approach, if readers would like more information, then please browse through the rest of this blog and the links to other resources that it contains (maybe this post would be a good place to start). What I will state is that a dashboard will only add value if it is part of an overall consistent approach to information, something that best practice indicates requires an Information Architecture. Anything else is simply going to be a pretty picture, signifying nothing.
Summary
So my advice to those seeking to build their first dashboard has three parts. First of all, keep it simple and identify a small group of measures and dimensions, which are highly pertinent to the core of the business and susceptible to graphical presentation. Second, dashboards are not a short-cut to management information Nirvana, they only really work when they are the final layer in a proper approach to information that spans all areas of the organisation. Finally, and partly driven by the first two observations, if you are in charge of building a dashboard, make sure that the plans you draw up reflect the complexity of the task and that you manage expectations accordingly.

")
")

")
")
")










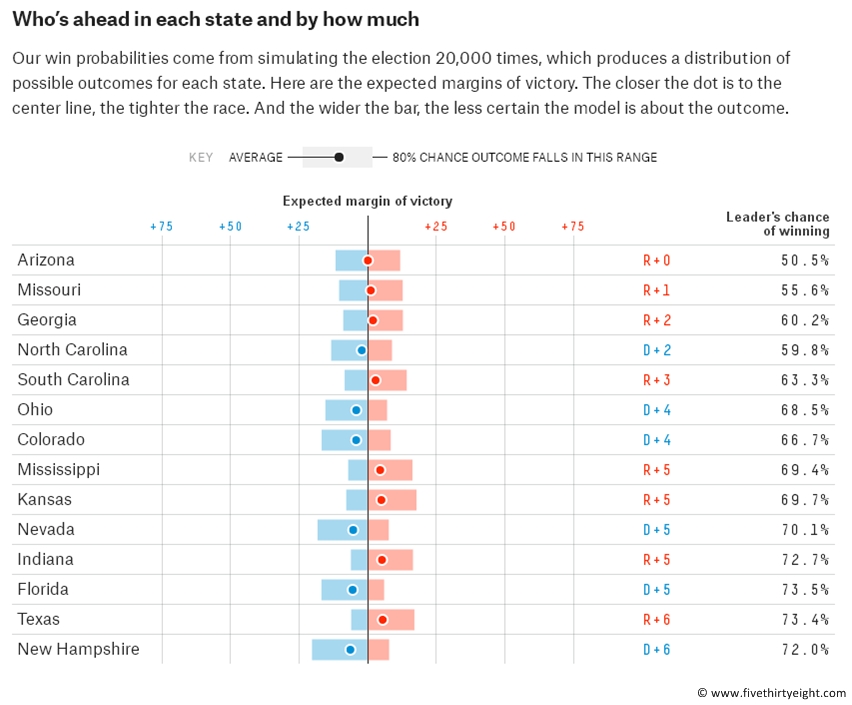




 myself; can't think where the inspiration for these characters came from.")

")



")

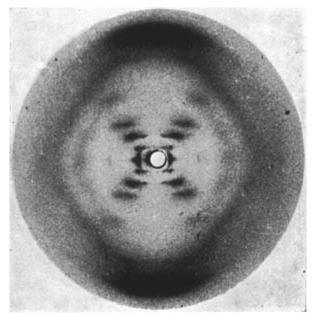


")

")







