The above diagram was compiled by Florence Nightingale, who was – according to The Font – “a celebrated English social reformer and statistician, and the founder of modern nursing”. It is gratifying to see her less high-profile role as a number-cruncher acknowledged up-front and central; particularly as she died in 1910, eight years before women in the UK were first allowed to vote and eighteen before universal suffrage. This diagram is one of two which are generally cited in any article on Data Visualisation. The other is Charles Minard’s exhibit detailing the advance on, and retreat from, Moscow of Napoleon Bonaparte’s Grande Armée in 1812 (Data Visualisation had a military genesis in common with – amongst many other things – the internet). I’ll leave the reader to look at this second famous diagram if they want to; it’s just a click away.
While there are more elements of numeric information in Minard’s work (what we would now call measures), there is a differentiating point to be made about Nightingale’s diagram. This is that it was specifically produced to aid members of the British parliament in their understanding of conditions during the Crimean War (1853-56); particularly given that such non-specialists had struggled to understand traditional (and technical) statistical reports. Again, rather remarkably, we have here a scenario where the great and the good were listening to the opinions of someone who was barred from voting on the basis of lacking a Y chromosome. Perhaps more pertinently to this blog, this scenario relates to one of the objectives of modern-day Data Visualisation in business; namely explaining complex issues, which don’t leap off of a page of figures, to busy decision makers, some of whom may not be experts in the specific subject area (another is of course allowing the expert to discern less than obvious patterns in large or complex sets of data). Fortunately most business decision makers don’t have to grapple with the progression in number of “deaths from Preventible or Mitigable Zymotic diseases” versus ”deaths from wounds” over time, but the point remains.
Data Visualisation in one branch of Science
Coming much more up to date, I wanted to consider a modern example of Data Visualisation. As with Nightingale’s work, this is not business-focused, but contains some elements which should be pertinent to the professional considering the creation of diagrams in a business context. The specific area I will now consider is Structural Biology. For the incognoscenti (no advert for IBM intended!), this area of science is focussed on determining the three-dimensional shape of biologically relevant macro-molecules, most frequently proteins or protein complexes. The history of Structural Biology is intertwined with the development of X-ray crystallography by Max von Laue and father and son team William Henry and William Lawrence Bragg; its subsequent application to organic molecules by a host of pioneers including Dorothy Crowfoot Hodgkin, John Kendrew and Max Perutz; and – of greatest resonance to the general population – Francis Crick, Rosalind Franklin, James Watson and Maurice Wilkins’s joint determination of the structure of DNA in 1953.
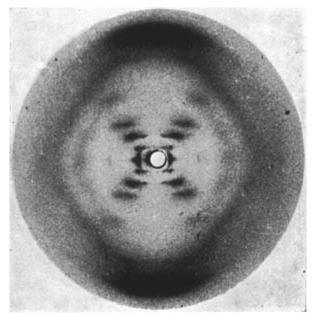
X-ray diffraction image of the double helix structure of the DNA molecule, taken 1952 by Raymond Gosling, commonly referred to as “Photo 51”, during work by Rosalind Franklin on the structure of DNA
While the masses of data gathered in modern X-ray crystallography needs computer software to extrapolate them to physical structures, things were more accessible in 1953. Indeed, it could be argued that Gosling and Franklin’s famous image, its characteristic “X” suggestive of two helices and thus driving Crick and Watson’s model building, is another notable example of Data Visualisation; at least in the sense of a picture (rather than numbers) suggesting some underlying truth. In this case, the production of Photo 51 led directly to the creation of the even more iconic image below (which was drawn by Francis Crick’s wife Odile and appeared in his and Watson’s seminal Nature paper[1]):
It is probably fair to say that the visualisation of data which is displayed above has had something of an impact on humankind in the fifty years since it was first drawn.
Modern Structural Biology
Today, X-ray crystallography is one of many tools available to the structural biologist with other approaches including Nuclear Magnetic Resonance Spectroscopy, Electron Microscopy and a range of biophysical techniques which I will not detain the reader by listing. The cutting edge is probably represented by the X-ray Free Electron Laser, a device originally created by repurposing the linear accelerators of the previous generation’s particle physicists. In general Structural Biology has historically sat at an intersection of Physics and Biology.
However, before trips to synchrotrons can be planned, the Structural Biologist often faces the prospect of stabilising their protein of interest, ensuring that they can generate sufficient quantities of it, successfully isolating the protein and finally generating crystals of appropriate quality. This process often consumes years, in some cases decades. As with most forms of human endeavour, there are few short-cuts and the outcome is at least loosely correlated to the amount of time and effort applied (though sadly with no guarantee that hard work will always be rewarded).
From the general to the specific
At this point I should declare a personal interest, the example of Data Visualisation which I am going to consider is taken from a paper recently accepted by the Journal of Molecular Biology (JMB) and of which my wife is the first author[2]. Before looking at this exhibit, it’s worth a brief detour to provide some context.
In recent decades, the exponential growth in the breadth and depth of scientific knowledge (plus of course the velocity with which this can be disseminated), coupled with the increase in the range and complexity of techniques and equipment employed, has led to the emergence of specialists. In turn this means that, in a manner analogous to the early production lines, science has become a very collaborative activity; expert in stage one hands over the fruits of their labour to expert in stage two and so on. For this reason the typical scientific paper (and certainly those in Structural Biology) will have several authors, often spread across multiple laboratory groups and frequently in different countries. By way of example the previous paper my wife worked on had 16 authors (including a Nobel Laureate[3]). In this context, the fact the paper I will now reference was authored by just my wife and her group leader is noteworthy.
The reader may at this point be relieved to learn that I am not going to endeavour to explain the subject matter of my wife’s paper, nor the general area of biology to which it pertains (the interested are recommended to Google “membrane proteins” or “G Protein Coupled Receptors” as a starting point). Instead let’s take a look at one of the exhibits.
The above diagram (in common with Nightingale’s much earlier one) attempts to show a connection between sets of data, rather than just the data itself. I’ll elide the scientific specifics here and focus on more general issues.
First the grey upper section with the darker blots on it – which is labelled (a) – is an image of a biological assay called a Western Blot (for the interested, details can be viewed here); each vertical column (labelled at the top of the diagram) represents a sub-experiment on protein drawn from a specific sample of cells. The vertical position of a blot indicates the size of the molecules found within it (in kilodaltons); the intensity of a given blot indicates how much of the substance is present. Aside from the headings and labels, the upper part of the figure is a photographic image and so essentially analogue data[4]. So, in summary, this upper section represents the findings from one set of experiments.
At the bottom – and labelled (b) – appears an artefact familiar to anyone in business, a bar-graph. This presents results from a parallel experiment on samples of protein from the same cells (for the interested, this set of data relates to degree to which proteins in the samples bind to a specific radiolabelled ligand). The second set of data is taken from what I might refer to as a “counting machine” and is thus essentially digital. To be 100% clear, the bar chart is not a representation of the data in the upper part of the diagram, it pertains to results from a second experiment on the same samples. As indicated by the labelling, for a given sample, the column in the bar chart (b) is aligned with the column in the Western Blot above (a), connecting the two different sets of results.
Taken together the upper and lower sections[5] establish a relationship between the two sets of data. Again I’ll skip on the specifics, but the general point is that while the Western Blot (a) and the binding assay (b) tell us the same story, the Western Blot is a much more straightforward and speedy procedure. The relationship that the paper establishes means that just the Western Blot can be used to perform a simple new assay which will save significant time and effort for people engaged in the determination of the structures of membrane proteins; a valuable new insight. Clearly the relationships that have been inferred could equally have been presented in a tabular form instead and be just as relevant. It is however testament to the more atavistic side of humans that – in common with many relationships between data – a picture says it more surely and (to mix a metaphor) more viscerally. This is the essence of Data Visualisation.
What learnings can Scientific Data Visualisation provide to Business?
Using the JMB exhibit above, I wanted to now make some more general observations and consider a few questions which arise out of comparing scientific and business approaches to Data Visualisation. I think that many of these points are pertinent to analysis in general.
Normalisation
Broadly, normalisation[6] consists of defining results in relation to some established yardstick (or set of yardsticks); displaying relative, as opposed to absolute, numbers. In the JMB exhibit above, the amount of protein solubilised in various detergents is shown with reference to the un-solubilised amount found in native membranes; these reference figures appear as 100% columns to the right and left extremes of the diagram.
The most common usage of normalisation in business is growth percentages. Here the fact that London business has grown by 5% can be compared to Copenhagen having grown by 10% despite total London business being 20-times the volume of Copenhagen’s. A related business example, depending on implementation details, could be comparing foreign currency amounts at a fixed exchange rate to remove the impact of currency fluctuation.
Normalised figures are very typical in science, but, aside from the growth example mentioned above, considerably less prevalent in business. In both avenues of human endeavour, the approach should be used with caution; something that increases 200% from a very small starting point may not be relevant, be that the result of an experiment or weekly sales figures. Bearing this in mind, normalisation is often essential when looking to present data of different orders on the same graph[7]; the alternative often being that smaller data is swamped by larger, not always what is desirable.
Controls
I’ll use an anecdote to illustrate this area from a business perspective. Imagine an organisation which (as you would expect) tracks the volume of sales of a product or service it provides via a number of outlets. Imagine further that it launches some sort of promotion, perhaps valid only for a week, and notices an uptick in these sales. It is extremely tempting to state that the promotion has resulted in increased sales[8].
However this cannot always be stated with certainty. Sales may have increased for some totally unrelated reason such as (depending on what is being sold) good or bad weather, a competitor increasing prices or closing one or more of their comparable outlets and so on. Equally perniciously, the promotion maybe have simply moved sales in time – people may have been going to buy the organisation’s product or service in the weeks following a promotion, but have brought the expenditure forward to take advantage of it. If this is indeed the case, an uptick in sales may well be due to the impact of a promotion, but will be offset by a subsequent decrease.
In science, it is this type of problem that the concept of control tests is designed to combat. As well as testing a result in the presence of substance or condition X, a well-designed scientific experiment will also be carried out in the absence of substance or condition X, the latter being the control. In the JMB exhibit above, the controls appear in the columns with white labels.
There are ways to make the business “experiment” I refer to above more scientific of course. In retail business, the current focus on loyalty cards can help, assuming that these can be associated with the relevant transactions. If the business is on-line then historical records of purchasing behaviour can be similarly referenced. In the above example, the organisation could decide to offer the promotion at only a subset of the its outlets, allowing a comparison to those where no promotion applied. This approach may improve rigour somewhat, but of course it does not cater for purchases transferred from a non-promotion outlet to a promotion one (unless a whole raft of assumptions are made). There are entire industries devoted to helping businesses deal with these rather messy scenarios, but it is probably fair to say that it is normally easier to devise and carry out control tests in science.
The general take away here is that a graph which shows some change in a business output (say sales or profit) correlated to some change in a business input (e.g. a promotion, a new product launch, or a price cut) would carry a lot more weight if it also provided some measure of what would have happened without the change in input (not that this is always easy to measure).
Rigour and Scrutiny
I mention in the footnotes that the JMB paper in question includes versions of the exhibit presented above for four other membrane proteins, this being in order to firmly establish a connection. Looking at just the figure I have included here, each element of the data presented in the lower bar-graph area is based on duplicated or triplicated tests, with average results (and error bars – see the next section) being shown. When you consider that upwards of three months’ preparatory work could have gone into any of these elements and that a mistake at any stage during this time would have rendered the work useless, some impression of the level of rigour involved emerges. The result of this assiduous work is that the authors can be confident that the exhibits they have developed are accurate and will stand up to external scrutiny. Of course such external scrutiny is a key part of the scientific process and the manuscript of the paper was reviewed extensively by independent experts before being accepted for publication.
In the business world, such external scrutiny tends to apply most frequently to publicly published figures (such as audited Financial Accounts); of course external financial analysts also will look to dig into figures. There may be some internal scrutiny around both the additional numbers used to run the business and the graphical representations of these (and indeed some companies take this area very seriously), but not every internal KPI is vetted the way that the report and accounts are. Particularly in the area of Data Visualisation, there is a tension here. Graphical exhibits can have a lot of impact if they relate to the current situation or present trends; contrawise if they are substantially out-of-date, people may question their relevance. There is sometimes the expectation that a dashboard is just like its aeronautical counterpart, showing real-time information about what is going on now[9]. However a lot of the value of Data Visualisation is not about the here and now so much as trends and explanations of the factors behind the here and now. A well-thought out graph can tell a very powerful story, more powerful for most people than a table of figures. However a striking graph based on poor quality data, data which has been combined in the wrong way, or even – as sometimes happens – the wrong datasets entirely, can tell a very misleading story and lead to the wrong decisions being taken.
I am not for a moment suggesting here that every exhibit produced using Data Visualisation tools must be subject to months of scrutiny. As referenced above, in the hands of an expert such tools have the value of sometimes quickly uncovering hidden themes or factors. However, I would argue that – as in science – if the analyst involved finds something truly striking, an association which he or she feels will really resonate with senior business people, then double- or even triple-checking the data would be advisable. Asking a colleague to run their eye over the findings and to then probe for any obvious mistakes or weaknesses sounds like an appropriate next step. Internal Data Visualisations are never going to be subject to peer-review, however their value in taking sound business decisions will be increased substantially if their production reflects at least some of the rigour and scrutiny which are staples of the scientific method.
Dealing with Uncertainty
In the previous section I referred to the error bars appearing on the JMB figure above. Error bars are acknowledgements that what is being represented is variable and they indicate the extent of such variability. When dealing with a physical system (be that mechanical or – as in the case above – biological), behaviour is subject to many factors, not all of which can be eliminated or adjusted for and not all of which are predictable. This means that repeating an experiment under ostensibly identical conditions can lead to different results[10]. If the experiment is well-designed and if the experimenter is diligent, then such variability is minimised, but never eliminated. Error bars are a recognition of this fundamental aspect of the universe as we understand it.
While de rigueur in science, error bars seldom make an appearance in business, even – in my experience – in estimates of business measures which emerge from statistical analyses[11]. Even outside the realm of statistically generated figures, more business measures are subject to uncertainty than might initially be thought. An example here might be a comparison (perhaps as part of the externally scrutinised report and accounts) of the current quarter’s sales to the previous one (or the same one last year). In companies where sales may be tied to – for example – the number of outlets, care is paid to making these figures like-for-like. This might include only showing numbers for outlets which were in operation in the prior period and remain in operation now (i.e. excluding sales from both closed outlets or newly opened ones). However, outside the area of high-volume low-value sales where the Law of Large Numbers[12] rules, other factors could substantially skew a given quarter’s results for many organisations. Something as simple as a key customer delaying a purchase (so that it fell in Q3 this year instead of Q2 last) could have a large impact on quarterly comparisons. Again companies will sometimes look to include adjustments to cater for such timing or related issues, but this cannot be a precise process.
The main point I am making here is that many aspects of the information produced in companies is uncertain. The cash transactions in a quarter are of course the cash transactions in a quarter, but the above scenario suggests that they may not always 100% reflect actual business conditions (and you cannot adjust for everything). Equally where you get in to figures that would be part of most companies’ financial results, outstanding receivables and allowance for bad debts, the spectre of uncertainty arises again without a statistical model in sight. In many industries, regulators are pushing for companies to include more forward-looking estimates of future assets and liabilities in their Financials. While this may be a sensible reaction to recent economic crises, the approach inevitably leads to more figures being produced from models. Even when these models are subject to external review, as is the case with most regulatory-focussed ones, they are still models and there will be uncertainty around the numbers that they generate. While companies will often provide a range of estimates for things like guidance on future earnings per share, providing a range of estimates for historical financial exhibits is not really a mainstream activity.
Which perhaps gets me back to the subject of error bars on graphs. In general I think that their presence in Data Visualisations can only add value, not subtract it. In my article entitled Limitations of Business Intelligence I include the following passage which contains an exhibit showing how the Bank of England approaches communicating the uncertainty inevitably associated with its inflation estimates:
Business Intelligence is not a crystal ball, Predictive Analytics is not a crystal ball either. They are extremely useful tools […] but they are not universal panaceas.
An inflation prediction from The Bank of England Illustrating the fairly obvious fact that uncertainty increases in proportion to time from now.
[…] Statistical models will never give you precise answers to what will happen in the future – a range of outcomes, together with probabilities associated with each is the best you can hope for (see above). Predictive Analytics will not make you prescient, instead it can provide you with useful guidance, so long as you remember it is a prediction, not fact.
While I can’t see them figuring in formal financial statements any time soon, perhaps there is a case for more business Data Visualisations to include error bars.
In Summary
So, as is often the case, I have embarked on a journey. I started with an early example of Data Visualisation, diverted in to a particular branch of science with which I have some familiarity and hopefully returned, again as is often the case, to make some points which I think are pertinent to both the Business Intelligence practitioner and the consumers (and indeed commissioners) of Data Visualisations. Back in “All that glisters is not gold” – some thoughts on dashboards I made some more general comments about the best Data Visualisations having strong informational foundations underpinning them. While this observation remains true, I do see a lot of value in numerically able and intellectually curious people using Data Visualisation tools to quickly make connections which had not been made before and to tease out patterns from large data sets. In addition there can be great value in using Data Visualisation to present more quotidian information in a more easily digestible manner. However I also think that some of the learnings from science which I have presented in this article suggest that – as with all powerful tools – appropriate discretion on the part of the people generating Data Visualisation exhibits and on the part of the people consuming such content would be prudent. In particular the business equivalents of establishing controls, applying suitable rigour to data generation / combination and including information about uncertainty on exhibits where appropriate are all things which can help make Data Visualisation more honest and thus – at least in my opinion – more valuable.
The list of scientists involved in the development of X-ray Crystallography and Structural Biology which was presented earlier in the text encompasses a further nine such laureates (four of whom worked at my wife’s current research institute), though sadly this number does not include Rosalind Franklin. Over 20 Nobel Prizes have been awarded to people working in the field of Structural Biology, you can view an interactive time line of these here.
[4]
The intensity, size and position of blots are often digitised by specialist software, but this is an aside for our purposes.
[5]
Plus four other analogous exhibits which appear in the paper and relate to different proteins.
[6]
Normalisation has a precise mathematical meaning, actually (somewhat ironically for that most precise of activities) more than one. Here I am using the term more loosely.
[7]
That’s assuming you don’t want to get into log scales, something I have only come across once in over 25 years in business.
[8]
The uptick could be as compared to the week before, or to some other week (e.g. the same one last year or last month maybe) or versus an annual weekly average. The change is what is important here, not what the change is with respect to.
[9]
Of course some element of real-time information is indeed both feasible and desirable; for more analytic work (which encompasses many aspects of Data Visualisation) what is normally more important is sufficient historical data of good enough quality.
[10]
Anyone interested in some of the reasons for this is directed to my earlier article Patterns patterns everywhere.
I was flattered to be included in the recent list of the 23 most influential BI bloggers published by Better Buys. To be 100% honest, I was also a little surprised as, due to other commitments, this blog has received very little of my attention in recent years. Taking a glass half full approach, maybe my content stands the test of time; it would be nice to think so.
It was also good to be in the company of various members of the BI community whose work I respect and several of whom I have got to know on-line or in person. These include (as per the original article, in no particular order):
* You can see Bruno and me talking on Microsoft’s YouTube channel here.
BI Software Insight helps organizations make smarter purchasing decisions on Business Intelligence Software. Their team of experts helps organizations find the right BI solution with expert reviews, objective resource guides, and insights on the latest BI news and trends.
Back in 2010 I posted a piece called Patterns patterns everywhere which used the entry point of various articles on a number of web-sites relating to the, then current, Eyjafjallajokull eruption. I went ont to reference – amongst other phenomena, the weather.
The incomparable Randall Munroe from xkcd.com has just knocked my earlier work into a cocked hat with his (perhaps unsurprisingly) much more laconic observations from last Friday, which are instead inspired by the recent cold snaps in the US:
Copyright xkcd.com
This image has been rearranged to fit in to the confines of peterjamesthomas.com
Back in July 2012 in A William Tell Moment? I got a little carried away about the potential convergence between tablets and personal computers. Nearly a year later – and with the Surface Pro only becoming available in my native UK last month – I probably know better. The following is therefore a more balanced piece.
It’s been a while since I put finger-tip to keyboard on this web-site. The occurrence which motivated me to do so was the arrival of my first new home computer since 2008 (yes unfortunately dear reader, the author is that much of a Luddite). The time since 2008 has seen a lot of changes in the technology sphere, notably the rise of the tablet (at probably the third time of asking) and the near ubiquity of end user computing. Certainly in response to the former (and maybe with some influence from the latter) my new laptop (if you can so describe a 17.3” desktop replacement) came with Windows 8 pre-installed.
I am obviously several months too late for my review of Microsoft’s latest OS to have much resonance and my brief comments here have no doubt been offered up by other pundits already. What I want to do instead is perhaps try to tie Windows 8 together with some broader trends and explore just how weird and polarised the technology market has become recently. However, some brief initial commentary on Windows 8 is perhaps pertinent.
The main thrust of Windows 8 is for Microsoft to remain relevant, perhaps not so much in its traditional arena of PC computing, but in the newer world of tablet and mobile computing. I’m sure some tablet fans may take issue with my observation, but my opinion is that Windows 8 is trying to do two, potentially incompatible, things: to be relevant to content creators and to content consumers. I am sure there are all sorts of examples of people creating amazing content on their iPads or Android tablets, however perhaps the surprise here is that it is done at all, rather than done well[1].
Regardless of some content creation doubtless occurring on tablets, I stand by my assertion that they are essentially platforms for the consumption of content; be that web-pages (sometimes masquerading as apps), games, videos, music, or increasingly feedback from the ever increasing range of sensors providing information about everything from the device’s location to its owner’s current heart rate. The content that is consumed on tablets is – in most cases – created on other types of devices; often the quotidian ones which have physical keyboards and pointing devices which allow for precision work.
In the past, the dichotomy between content creators and content consumers has been somewhat masked by them employing similar tools. Of course every content creator is also a content consumer, but it has always (“always” of course being an interesting word when what I probably mean is “since the Internet became mainstream”), been the case that there were significantly more of the latter than the former[2]. What was different historically was that both creators and consumers used the same kit; PCs of some flavour[3] (though maybe the former had better processors and more memory on their machines). The split in roles was evident (if it was evident at all) in computers that were only ever used to surf, do e-mail and write the occasional letter; there were probably an awful lot of these. We had a general purpose computing platform (the PC) which was being under-utilised by the majority of people who owned one.
The eventual adoption of tablets has changed this dynamic. Although of course many tablets have processors that previous generations of PCs could only have dreamed of, their focus is firmly on delivering only those elements of a PCs capabilities which most people use and eschewing those which the majority ignore. As always, specialisation and focus leads to superior execution. The author (no fan of Apple products in general) can confirm that an iPad is much more fit for purpose than a laptop when the purpose is watching a film or TV show on a train or plane. Laptops can of course do this, but they are over-engineered for the task and also pretty bulky if all you want is to watch something. Having played Angry Birds on each of Android, iOS and web-versions on a laptop, the experience is best on the smaller, lighter, touch-based devices.
The reason that the sales of PCs have plummeted while those of tablets soar is not that tablets are better than PCs, nor is it even that they demystify computing in a way that their elder brethren fail to do (more on this later), but simply that tablets are more aligned with what the majority of people want from their computers; as above to be media platforms that allow basic surfing and e-mail. To borrow the phrase from the last paragraph, tablets are more fit for purpose if the purpose is consumption of content.
The flip side of this is what I am currently doing: namely writing this article, sourcing / editing / creating images to illustrate it and cutting some entry-level HTML in the process. I could of course do this on an iPad or Android tablet. However this is much like saying that you can (in extremis) use a foot-pump to re-inflate a car tyre, but why would you if you can make it to a garage / service station and get access to a machine that is dedicated to inflating tyres with greater efficiency. If there was no machine with a keypad to hand, then I might decide to write on an iPad, but it would be a frustrating and sub-optimal experience. PCs are more fit for purpose where the purpose is content creation.
However, we now reach a problem in economics. If we apply the Wikipedia percentages to content creators versus content consumers, then the split is (depending on which side of the fence you place editors) either 1 : 10 or 1 : 100. In either case, someone pitching hardware and software to a content creator is addressing a much smaller part of the marketplace than someone pitching hardware and software to content consumers; aka the mass market. This observation inexorably leads to the types of features and capabilities which will dominate any platforms aimed at general computer users; basically content consumers are king and content creators paupers.
Which returns me to Windows 8. The metro interface is avowedly designed for mobile devices with a touch-based interface. My new machine doesn’t have a touch screen. Why would I need one on a device that supports the much more efficient and precise input provided by a physical keyboard and mouse? Indeed, one of the nice things about my new laptop is its 1920×1080 screen, why would I want to cover this with as many annoying finger smudges as my iPad has when there are much better ways of interacting with the OS which also leave the monitor clean? In fact, on reflection, I guess that the majority of people and not just content creators would prefer a non-smeared screen most of the time.
There seem to be obvious usability snafus in Windows 8 as well. To highlight just one, if you move your mouse (aka finger) to the top right-hand side, one of the “charms” menus appears (I’d really like to know why Microsoft thought “charms” was a great name for this). But what is also at the top right-hand side of any maximised window? The close button of course. I have lost count of how many times I have wanted to close a programme and instead had the charming blue panel appear instead. I spent the first eight years of my career in commercial software development and fully appreciate that there is no such thing as bug-free code, however this type of glitch seems so avoidable that one has to question both Microsoft’s design and testing process.
Anyway, enough on the faults of Windows 8. In time I’ll get used to it just as I did with Windows 95, 97, XP and 7. Just as I have got used to each version of Excel being harder to use than the last for anyone that has a track record with the application. Of course I’ll get used to Excel 2013, what choice do I have? But this leads us into another economic dichotomy. Microsoft don’t need to win me over to Excel, I’m going to put up with whatever silly thing they do to it in the latest version because that’s a lower hurdle than learning another spreadsheet; even assuming that something like Google Docs offers the same functionality. The renewal rates for products like Excel must be 95% plus, this means that a vendor like Microsoft focusses instead on getting new business from people who don’t use their applications. If this means making the application “easier” for new users, then who cares if existing users are inconvenienced, it’s not like they are going to stop using the application.
As I alluded to above, a general claim made for tablets (and for the iPad in particular) is that they demystify computing, making it accessible to “regular people” (as an aside here we have the entire cool dude versus nerd advertising encapsulated in “I’m a Mac, he’s a PC”, something which I think Microsoft are to be lauded for lampooning in their later campaign). Instead I would argue that tablets offer a limited slice of what computers can do (the genius being that it is the slice that 90% or 99% of content consumers seem to want). They don’t make computing easier or more accessible, they make it more limited and sell this as a benefit using words like “elegant”, “stripped-down” or “minimalist”.
Tablets clearly fill a large market need, I use them myself. However, my Window-centred gripe is when I have to buy a product (a PC) whose basic operation is dictated by a function (content consumption) for which the machine is over-engineered, whereas the function for which a PC is perfect (content creation) is symmetrically and even systematically compromised.
As things stand, maybe Microsoft should not be so concerned about losing the mobile and tablet market (perhaps for them it is already too late). Instead it could be argued that they should be more worried about, though a lack of attention to the needs of their core users, forfeiting the PC market which they have dominated for so long and in which their products (pre-Windows 8 at least) were the ones best suited to the job at hand.
The recent launch of the Xbox One (whatever happened to sequential numbering by the way?) was roundly condemned by gamers as focussing too much on the new console being a media hub (again attracting new users) rather than a gaming platform (again ignoring the needs of existing users). At least one cannot accuse Microsoft of being inconsistent, but alienating existing customers is seldom a great long-term strategy for a business.
Notes
[1]
Let’s glide seamlessly over Samuel Johnson’s original application of this image to comment on women preachers; the 18th Century is certainly a foreign country and I’m rather glad that we now [mostly] do things differently here.
[2]
By way of illustration, Wikipedia tends to assume the 90-9-1 rule. 1% of users create content, 9% edit or otherwise modify content, the rest consume.[citation needed]
[3]
Although maybe the term PC has become synonymous with Wintel based machines, I include here personal computers running flavours of UNIX such as Mac OS and Linux.
I was recently invited by recruitment consultancy La Fosse to chair an roundtable event for fellow Business Intelligence professionals. We held the meeting last Thursday evening in London. There was a good turn out with delegates representing the following industries (number of attendees in brackets):
Insurance and affiliated (5, including me)
Investment Banking and affiliated (2)
Manufacturing (2)
Media (2)
Aviation (1)
Public Sector (1)
On-line (1)
As chair there is always the dread of the tumbleweed moment; everyone staring at each other with nothing to say. However, I needn’t have worried as each of the group members had a lot to share based on their extensive and varied experiences in the area. We started at 6pm, rolled through the call for early departures at 7:45pm and dissolved into smaller groups around 8:30pm. As several people said via e-mail the next day, without journeys home to consider, we could have happily kept talking for several more hours.
There were a number of encouraging aspects to the event. First of all, in chatting to various people before we formally kicked off, I found that many (like me) had worked in a number of industries in addition to the one where they were currently employed. There was general agreement with my view that this can often broaden perspectives and that at least several central elements of BI are pretty transportable between different areas of business endeavour. Of course in-depth exposure to one sector is invaluable, but leavening this with a few years in different sorts of organisations can produce a more rounded individual with a wider range of experiences.
The second encouraging aspect was the nature of the conversations. There was little interest in the latest and greatest technological tools (though we did spend a bit of time on the almost mandatory topic of Big Data). Instead virtually everyone wanted to talk about the human aspects of their BI programmes; past and present. Questions included: how to generate enthusiasm; how to reflect business needs when these were often changing in line with rapidly shifting strategic and competitive environments; how to both provide payback and demonstrate that you were doing this; how to become an embedded part of the business, not a technology bystander. People were happy to offer examples of what had worked (and failed to work) for them and to enrich these with interesting anecdotes and pertinent analogies. I suppose if I achieved anything as chairman (and it was a relatively easy group to chair), this was to ensure that everyone had some airtime.
It would be untrue to say that there was unanimity on all points; some things had worked for some people, different ones for others. However it is fair to say that, at least at a conceptual level, there was a degree of commonality of opinion about success factors. More positively (and in line with my now ancient article A bad workman blames his [Business Intelligence] tools), no one felt that the answer to the challenges they faced was the latest dashboard or data visualisation tool. Most people felt that we have had the technological tools and general knowhow to succeed in information-centric programmes for years, if not decades. Reasons for success and failure have always been (and remain) in the rather messier areas of business engagement, sound programme management, strong communications, pragmatism and responsiveness to developing needs.
While the fact that so many BI practitioners shared these (in my opinion) well-informed views is perhaps not great news for the vendors of information platforms and tools, it does suggest that – after a troubled childhood – BI is coming of age. In established and well-understood areas of business what counts is not technology, but how you apply it and align this with what people need. If this approach is becoming mainstream in Business Intelligence, and on the evidence of last week’s meeting is it, then maturity seems to be within reach; truly an encouraging thought.
This IRM UK event will be taking place in central London from the 5th to 7th November 2012. As ever, it is co-located with the IRM Data Management & Information Quality Conference. Full details may be obtained from the IRM conference web-site here.
The title of my presentation is: “Formulating a Business Intelligence / Data Warehousing Strategy”.
This blog primarily deals with matters relating to business, technology and change; obviously with a major focus on how information provision overlaps with each of these. However there is the occasional divertimento relating to mathematics, physical science, or that most recent of -ologies, social media.
The following article could claim some connections with both mathematics and social media, but in truth relates to neither. Its focus is instead on irritation, specifically a Facebook meme that displays the death-defying resilience of a horror movie baddie. My particular bête noire relates to the following diagram, which appears on my feed more frequently that adverts for “Facebook singles”:
It is generally accompanied by some inane text, the following being just one example:
I got into a heated battle with a friend over this… I got 24 she say’s 25. How many squares do you see?
Nice grocer’s apostrophe BTW!
I realise that the objective is probably to encourage people to point out the error in the ways of the original poster; thereby racking up comments. However 24?, 25??, really???, really, really????
Let’s break it down…
Well there is clearly one big square (a 4×4 one) staring us in the face as shown above. Let’s move on to a marginally less obvious class of squares and work these through in long-hand. The squares in this class are all 3×3 and there are 4 of them as follows:
1…
2…
3…
4…
Adding the initial 4×4 square, our running total is now 5.
The next class is smaller again, 2×2 squares. The same approach as above works, not all the class members are shown, but readers can hopefully fill in the blanks themselves.
1…
2…
Skip a few…
9…
Adding our previous figure of 5 means our running total is now 14; we are approaching 24 and 25 fast, which one is it going to be?
The next class is the most obvious, the sets of larger 1×1 squares.
It doesn’t require a genius to note that there are 16 of these. Oh dear, the mid-twenties estimates are not looking so good now.
Also we shouldn’t forget the two further squares of the same size (each of which is split into smaller ones), one of which is shown in the diagram above.
Our previous total was 14 and now 14 + 16 + 2 = 32.
Finally there is the second set of 1×1 squares, the smaller ones.
It’s trivial to see that there are 8 of these.
Adding this to the last figure of 32 we get a grand total of 40, slightly above both 24 and 25.
Perhaps the only thing of any note that this rather simple exercise teaches us is the relation to sums of squares, inasmuch as part of the final figure is given by: 1 + 4 + 9 + 16, or 12 + 22 + 32 + 42 = 30. Even this is rather spoiled by introducing the intersecting (and interloping) two squares that are covered last in the above analysis.
Oh well, at least now I never have to comment on this annoying “puzzle” again, which is something.
Michael Koploy of on-line technology consulting company Software Advice recently asked me, together with four other people from the Business Intelligence / Data Warehousing community, to contribute some definitions of commonly-used technology jargon pertinent to our field. The results can be viewed in his article, BI Buzzword Breakdown. Readers may be interested in the differing, but hopefully complementary, definitions that were offered.
In jockeying for space with my industry associates, only one of my definitions (that relating to Data Mining) was used. Here are two others, which were left on the cutting room floor. Maybe they’ll make it to the DVD extras.
Big Data
Rather than having the entirely obvious meaning, has come to be associated with a set of technologies, some of them open source, that emerged from the needs of several of the major on-line businesses (Google, Yahoo, Facebook and Amazon) to analyse the large amount of data they had relating to how people interact with their web-sites. The area is often linked to Apache Hadoop, a low-cost technology that allows commodity servers to be combined to collectively to store large amounts of data, particularly where the structure of these varies considerably and particularly where there is a need to support unpredictably-growing volumes.
Data Warehouse
A collection of data, generally emanating from a number of different systems, which is combined to form a consistent structure suitable for the support of a variety of reporting and analytical needs. Most warehouses will have an element of data stored in a multi-dimensional format; i.e. one that is intended to support pivot-table like slicing and dicing. This is achieved using specific data structures: Fact tables, which hold figures, or measures (like profit, or sales, or growth); and dimension tables, which hold business entities, or dimensions (like countries, weeks, product lines, salesman etc.). The dimensions are often nested into hierarchies, such as Region => Country => City => Area. Warehouse data is generally leveraged using traditional reports, On-Line Analytical Processing (OLAP) and more advanced analytical approaches, such as data mining.
The above comments are perhaps most notable for representing my first reference to the latest information hot topic, the rather misleadingly named Big Data. To date I have rather avoided the rampaging herd in this area – maybe through fear of being crushed in the stampede – but it is probably a topic to which I will return once there is less hype and more substance to comment on.
Disclosure #1: As is inevitable for any IT professional, the author has used Microsoft’s enterprise products at many points during his career. As is inevitable for any sentient inhabitant of planet Earth, he has used their more broadly targeted software on a daily basis for longer than he can remember (many of the images on this site were created via the combination of Visio supplemented by the non-MS – and horribly old school – PaintShop Pro). He has no direct holdings in Microsoft, but undoubtedly must have some interest in the company indirectly via pension or investment funds; something that would probably also hold for all of Microsoft’s main competitors.
Disclosure #2: Beyond this, the author has been featured in a Microsoft Business Intelligence video; but this did not relate to the endorsement of any Microsoft product.
Disclosure #3: The author can proudly state that he has never owned any Apple product, but does periodically use a corporate iPad and has occasional access to an iPhone owned by someone else (doesn’t everyone?). Rumours that he has three stars at all levels of Angry Birds Space have not been independently verified.
Disclosure #4: The author has neither seen directly, nor further still touched a Surface – though if Microsoft wanted to remedy this situation, he would at the very least guarantee them a thorough (and professionally neutral) review.
It’s somewhat odd to report that I am rather excited by an announcement Redmond’s finest (with apologies to Nintendo America). Like many people I have had a love / hate relationship with the Washington behemoth for more years than I care to remember; having lived through the hype and subsequent let down of every MS O/S since 95. Come to think of it, as my girlfriend suggests, that would be a great slogan: “Microsoft – disappointing expectant millions since 1995!”
Maybe my general take on the firm’s recent output was best summed up by another noted industry commentator:
“My new computer came with Windows 7. Windows 7 is much more user-friendly than Windows Vista. I don’t like that.”
However, having had to put up with umpteen technology industry commentators sycophantically parroting Cupertino’s “the PC is dead, long live the tablet” mantra over the last few years, it is gratifying to think that there may (and I stress may) soon be a tablet available that is also a proper computer; i.e. one that you can actually do useful things on, rather than fashion accessory cum entertainment centre with a bad browser and support for only for the type of games that you can play equally well on your Facebook page. Please don’t get me wrong, as I mention above, I’m as much a fan of Angry Birds as the next guy, but as a lapsed gamer myself I can hopefully tell the difference between a gaming platform and an amusing diversion.
The ubiquitous iPad has been touted as bringing computing to the non-technically literate masses. Instead it has brought a grossly watered down ability to conspicuously consume at the expense of any support for creative activities. In my opinion, the oft repeated phrase that “there’s an app for that” tends only to work when “that” is a pretty narrow range of activities. I’m on my iPad; I want to update my Facebook status – tick; I want to upload an un-edited photo I just took – tick (on some models at least); I want to tweet something (maybe even including a URL I have copied from elsewhere) – tick (fiddly as this might be); I want to write a lightly formatted blog post without too many typos and which includes a couple of images I have either lightly-edited, or created from scratch – um…
That’s where most types of tablet seem to hit their limit, Android as well as iOS (and undoubtedly Amazon’s offering as well); casual surfing (be it browser or other app based), checking mail, watching a movie, working out what street I am on, simple social medial interactions. These things are all OK and all are light on content creation. Anything else (even a lengthy e-mail – something I specialise in) quickly becomes a chore. Pointedly, all of the things that I have mentioned working well on tablets, also work at least to close to as well on a decent sized smart ‘phone, which also has the benefit of actually being portable and also (at least in most cases) of being a ‘phone.
So, given my zeitgeist-busting lack of whelmedness with tablets, where does that leave Ballmer’s latest offering. Well, let’s discount the ARM-based, “me too” version (with apologies to my fellow inhabitants of Cambridge; East Anglia, not Massachusetts) and focus on the Ivy Bridge-powered Surface Pro. This is (as far as can be discerned from the [limited] information that Redmond have thusfar divulged) where the real attention will inevitably focus. As the BBC’s (oft lampooned) technology correspondent states:
“At one small business this week – my excellent local optician – I learned that the owner plans to replace all his PCs with Surface tablets when they come out. Why not go straight to iPads, I wondered – only to learn that just about every ophthalmic application was Windows-based.”
I.e. there are an awful lot of proper, grown-up applications out there which only work on the dreadfully uncool WinTel platform. Indeed, outside of the creative industries (like other parts of industry can’t be creative?) and parts of science that rely upon tuned-up versions of graphical software that emanates essentially from the former (or which were provided “free” back in the day by those awfully nice Apple chaps), most business-focussed software (that is not already web-based) is WinTel based.
The idea of a proper computer that can (as far as we can tell at present) support all of the above, plus coming in a conveniently portable tablet-like package; but – crucially – with adult input devices like (shock-horror) a keyboard and track-pad and (even more shock and even more horror) a DisplayPort port for those tasks (like many of mine) where at 10” monitor is way too small and (Nightmare on Elm Street levels of horror) a USB 3.0 port; sounds awfully like the tablet concept coming of age (or, for those with an historical bent, fulfilling the vision that Bill Gates originally outlined for the device, long before the late Steve Jobs imbued it with his irreplaceable and inimitable coolness).
Many much wiser commentators than me have stated that the Surface will live or die based on the quality and extent of the app ecosystem it develops around it. For me the Pro has all the apps you could ever need, the Windows ones that people use to actually do things.
Of course the devil is in those (perhaps worryingly as yet undisclosed) details. What will the precise specs of the Surface Pro processor and RAM be? What is the screen resolution? How long will the battery last? How good a keyboard substitute will the Type Cover be in practice? Why on Earth does the RT come with Office and the machine set up to run it properly apparently doesn’t? Will Metro be pleasurable to use in those (infrequent) moments when all you actually want is an entertainment platform? These will all become clear in time no doubt, and there is obviously more than enough scope for Microsoft to disappoint me again. However, at present I am holding on to the glimmer of hope that this time they have got it right. If they have, the Surface could be very good indeed. As Don Maclean never sang:
So bye bye to my Pad with an ‘i’
Get a Surface in to yer place
Won’t you give it a try
Those Angry Birds may may just have to fly
Singing this could be the tablet I’d buy
I quite like WordPress.com’s latest data visualisation tool, which allows you to see the spread of people reading your blog. The data only goes back to February 25th 2012 and presumably a number of hits can have no country attributed to them, but it’s still a nice addition and interesting for me to see the number of different places that readers come from.
Perhaps we’ll gloss over the Mercator Projection and also how annoying and fiddly the WordPress app for iOS is; then things are always harder on iPad – right?
")



")

")


































